AMD RX Vega性能解禁在即,相信大家一定很兴奋,“吹”了将近一年的Vega显卡终于要用真面目示人了。之前我们曾经用AMD Radeon Vega Frontier Edition开发者卡来打过游戏——《专业卡能不能打游戏?AMD Radeon Vega Frontier显卡性能测试》,发现其性能大约是在其竞争对手NVIDIA GTX 1080、GTX 1070之间,但部分游戏成绩甚至不如GTX 1070。经过向AMD驱动部门沟通得知,尽管Radeon Vega Frontier Edition驱动中拥有一个Gaming Mode,但是这个切换的仅仅是驱动UI界面,而非驱动本身,驱动还是偏向于专业开发者的方面,直接用于游戏是不合理的。因此我们决定让AMD Radeon Vega Frontier显卡做回本行工作——只做专业测试,6款专业测试软件共47个专业测试子项,并且携带上好朋友Radeon Pro Duo(Polaris 10 x2)以及假想敌NVIDIA Quadro P5000,三款专业卡将同场较量。

AMD Radeon Vega Frontier Edition:

Vega显卡作为AMD今年重头大写之一,当然是万众期待。Radeon Vega Frontier作为首批与我们见面的Vega架构显卡,它身上的秘密已经被探索得非常透彻了。
Radeon Vega Frontier Edition首先可以确认是满血版的Vega核心,也就是64组NCU单元,每组64个流处理器共同构成4096个流处理器,256个纹理单元,64个光栅单元,4MB的L2缓存。8GB的HBM 2显存,位宽为2048bit,而显存带宽高达484GB/s。
其余更多新特性可以参考上一期的超能课堂《超能课堂(99):揭秘AMD Radeon Vega架构新玩意》,绝大部分疑惑都可以在里面找到答案。
这里我们主要谈一下Vega架构中关于NCU单元(Next-Generation Compute Engine)的事情,一般来说3D游戏渲染对于FP32单精度要求是比较高的,不过在专业深度计算上对FP16半精度更为青睐,毕竟性能好、功耗低,也因此AMD在Vega最新的微架构(估计会延续过去叫GCN X.X,暂未公布)中引入了紧缩的半精度计算支持,可以灵活地使用NCU单元的ALU算术逻辑单元支持FP16、FP32计算。因此基于Vega架构的Radeon Instinct MI25计算卡其FP32单精度浮点性能12.5TFLOPS,而半精度FP16性能直接翻倍到25TFLOPS。
稍微遗憾的是,目前除了实际应用中使用到FP16单元,可复现、标准FP16性能测试基本是没有的,即使有也是模拟出来FP16性能,并不准确,如果大家有什么好的测试意见,欢迎向小超哥微信9501417提出。
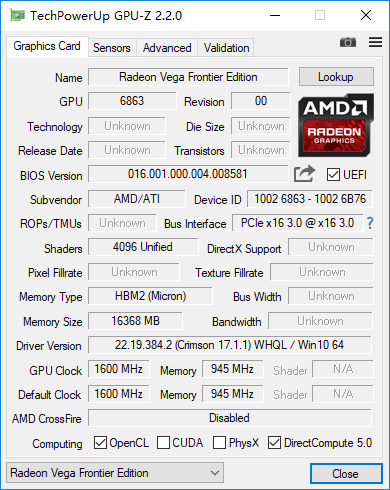
测试驱动为:Radeon™ Vega Frontier Edition Driver 17.6
AMD Radeon Pro Duo:

最近Vega显卡锋芒毕露,大家注意力都被吸引过去了,甚至不知道有一张双Polaris 10核心的专业卡存在吧。虽然它命名为Radeon Pro Duo,但此Radeon Pro Duo非彼Radeon Pro Duo,不是我们之前熟知的基于双Fiji核心的Radeon Pro Duo。
新的Polaris架构Radeon Pro Duo拥有36*2组CU单元,共2304*2个流处理器,核心频率1243MHz,单精度浮点运算能力为11.45TFLOPS(旧版Radeon Pro Duo为16.4TFLOPS),显存位宽256bit*2,显存频率1750MHz,显存带宽448GB/s(旧版Radeon Pro Duo为512GB/s,因为用的HBM显存)。
从性能上来看,当然是旧版的Radeon Pro Duo更胜一筹,但是付出了以功耗、散热为代价,350W的TDP以及水冷散热都是玩家的痛。使用Polaris架构的新Radeon Pro Duo显然更加符合实际需求,尽管性能能够缩水了1/3。
不过在NVIDIA、AMD均宣布不再重点支持多卡SLI、Crossfire以后,两家公司将会以发展更高性能单核心显卡为主要目标。毕竟多卡互联之后性能提升大家有目共睹,1+1=1.4已经是非常好的结果,剩下全都要靠驱动重点优化才有“神油”效果,在这方面付出太多显然太不划算了。
尽管双芯卡性能要比一般的2Ways Crossfire性能要好,但是并不适合游戏,对于专业级用户来说还是有一定价值,毕竟部分渲染、计算就是需要暴力堆砌流处理器驱动,越多越好。这种任务的流程简单,就像跑着固定的流水线上,不像游戏场景那么复杂多变,只要处理单元越多,性能当然越好。
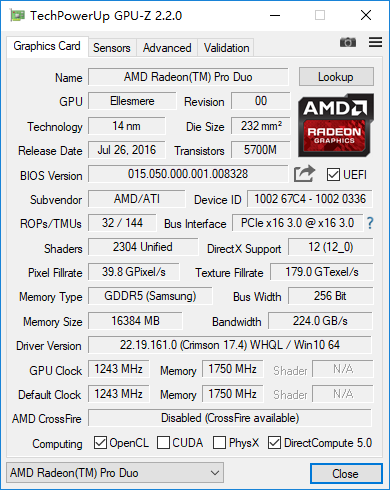
测试驱动为:Radeon Pro Software Enterprise Driver 17.Q3
NVIDIA Quadro P5000:

Quadro P5000显卡有一个大家都熟悉的身份,那就是Pascla显卡的先锋GTX 1080,他们直接的硬件规格都是一模一样的——GP104-400核心。
GP104-40核心拥有20组SM单元,每组SM单元有128个CUDA核心,一共2560个,首次搭配了与美光联合开发的8GB GDDR5X显存,主要是显存频率更高了,飙到10Gbps,间接地弥补了GDDR5显存带宽比不过HBM显存弊端。而作为专业卡的Quadro P5000显然对显存大小更为敏感,NVIDIA为其增加了一倍的GDDR5X显存,双面布局共16GB。
如果你要问,Quadro P5000用的GP104-400与Quadro P6000的GP100核心有什么区别?这个区别可就大了,GP104本来就是针对游戏市场,还记得Maxwell架构显卡超高能耗比怎么来的吗?就是砍FP64双精度单元,从GP100核心FP32:FP64的1:2超高比例,砍到GP104-400的1:32,这个刀法可是非常厉害的。
而AMD Radeon Pro Duo的FP32:FP64比例为1:16,而AMD Radeon Vega Frontier Edition目前还不好说,AMD官方还没有公布详细的架构示意图。
不过Vega架构总算是引入了FP16半精度单元,如果有需要也可以重新“组装”成FP32单精度单元,而NVIDIA引入FP16单元已经有相当长一段时间,因为NVIDIA涉足人工智能、大数据处理、机器学习已经挺久了,这些应用对于运算精度要求并不好,FP16不仅速度快,而且功耗更低,非常适合。NVIDIA为了应付即将爆发的深度学习领域需求,已经大胆地在下一代Volta架构的Tesla V100引入了Tensor单元,这种单元与深度学习计算性能高度相关,性能非常可怕,在FP32:FP64:Tensor单元比例为8:4:1下,Tensor性能就高达120TFLOPS,NVIDIA已经未雨绸缪。
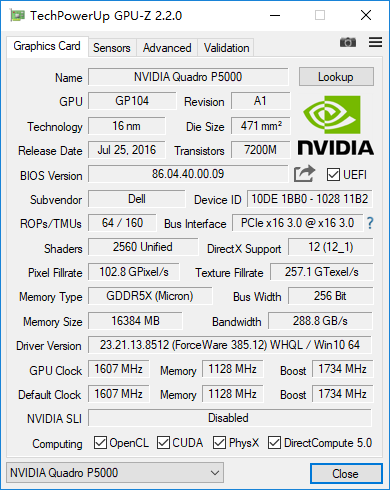
测试驱动为:QUADRO DESKTOP DRIVER RELEASE 384 U2 (385.12)
测试平台:


AIDA64是我们熟知的一个测试软硬件系统信息工具,内置了多个简易拷机、Benchmark测试程序,可以供我们快速查看硬件的真实性能水平。
而一般测试GPU、APU性能都会用到AIDA64 GPGPU Benchmark,这是一个相当基础的测试程序,包含了显存读写复制速度、单/双精度浮点性能/应用、24/32/64位整数运算、AES-256/SHA-1 Hash性能运算成绩。
这个环节我们只比较Single-Precision FLOPS(单精度浮点性能)、Double-Precision FLOPS(双精度浮点性能)、Single-Precision Julia(单精度浮点应用,主要是运行游戏时用到)、Double-Precision Madel(双精度浮点应用,主要影响Matlab、流体力学绘图这类对于高精度的科学运算上)。
小总结:从AIDA64 GPGPU测试成绩来看,AMD Radeon Vega Frontiers Edition似乎大获全胜,无论是单精度、双精度理论性能还是应用场景性能,但是这个并不符合实际情况,虽然P5000浮点性能确实落后于AMD Radeon Vega Frontiers Edition,但是这个幅度太大了,重复测试也是如此。显然是测试具有一定偏向性(或者NVIDIA Quadro P5000没有设置好)。

LuxMark考验的是OpenCL运算能力,设置为GPU-Only模式,即可单纯考验显卡GPU的性能。进入软件后单独测试三个场景:Hotel lobby、Neuman TLM-102 SE、LuxBall HDR。
小总结:Luxmark显然能更加重复调动Radeo Pro Duo的性能,成绩远超其余两张卡成绩,NVIDIA Quadro P5000依然大幅度落后。

CineBench测试在很多CPU、GPU性能展示或者是超频环节中经常可以看到它的身影,使用针对电影电视行业开发的Cinema 4D特效软件引擎,是一套具有相当大说服力的CPU和显卡测试程序。测试分别针对处理器和显卡的性能指标,有两种测试方式,既可以测试CPU单线程/多线程邢恩能够,可以用使用显卡运行程序得出OpenGL性能。在OpenGL中,会实时渲染一段高精度跑车的视频。

小总结:Cinebench R15作为最常见的测试软件,显卡测试使用的是OpenGL,在这次显卡测试NVIDIA P5000成绩就要好于Vega Frontier,不过这种测试对于AMD Radeon Pro Duo双芯卡就是不太友好,软件会识别成两张显卡,测试的时候只能调动到一个核心运算,所以成绩偏差。
ComputeMark由捷克硬件和游戏网站CzechGamer.com的Robert Varga完成开发,核心技术来源于Jan Vlietinck的Fluid3D Demo,号称是“第一个百分之百的DX11 Compute Shader(计算着色器)基准测试工具”,能够调动99%的GPU资源,CPU占用率极低,重点考察显卡GPU通用计算性能。
小总结:ComputeMark测试针对的是计算着色单元,数量越多自然越占优势。按道理,应该是Radeon Pro Duo占优,可惜ComputeMark仍然仅支持一个核心测试,最终Vega Frontier以1818分第一,Quadro P5000第二

Sisoftware Sandra 2017是目前最强大、最优秀的一款计算机硬件检测与性能测试软件,拥有系统性能测试、硬件检测、软件检测、电脑高强度压力测试、cpu显卡压力测试等30多个功能模块,并支持客户端和服务器两种工作模式,能够全面帮助用户检测计算机硬件和软件,并以直观的图表方式展示你的电脑各种性能。
最方便的还是Sisoftware拥有自己的产品数据库,你可以联网下载数据进行直观对比,从而或者你的硬件水平处于什么样的高度,并且及时发现问题。
本次测试中,我们挑选了其中7个与显卡性能有密切关系的测试项目,包括:
Sisoftware Sandra 2017 SP1-Processing测试——通用计算,单/双/四/精度浮点性能。
总结:单精度测试结果是没有问题的,而且成绩都超过官方提供的数据,但是双/四精度上P5000再次出现了问题,双精度成绩只有0.44GPixel/s,远落后于其余两张卡,四精度成绩也是如此。
Sisoftware Sandra 2017 SP1-Cryptography测试——加密/解密运算性能,包含AES-256和SHA2-256
加密测试中,无论是AES还是SHA2算法,Vega Frontier都以绝对优势领先,很多人都在说Vega显卡挖矿性能如何厉害,这个也其实关系显卡的哈希算法性能,根据小编测试,使用ClayMore V9.8软件挖ETH,性能大概在35-38MH/S左右,远没有传闻中的100MH/s那么高。
Sisoftware Sandra 2017 SP1-Financial Analysis测试财务分析,包含一些比较复杂的金融模型,例如布莱克—斯克尔斯-默顿期权定价模型、欧式二次项定价模型、欧式蒙特卡洛期权定价模型
财务分析测试中都是一些比较复杂的金融模型算法,AMD显卡都有非常好的表现,NVIDIA性能稍差。
Sisoftware Sandra 2017 SP1-Scientific Analysis测试——科学分析,如矩阵乘法运算、快速傅里叶变换、N体数值模拟计算
Sisoftware Sandra 2017 SP1-Image Processing测试——图像处理,使用各种卷积滤波、索贝尔算子、中值滤波、量化滤波、随机算子进行图像运算处理
在图像渲染测试环节,测试场景很多,都是使用不同算子对大尺寸图像进行计算出新的图像,可以看到不同显卡对于算子、滤波器有着不同性能表现。
Sisoftware Sandra 2017 SP1-Video Shader Compute测试——视频渲染性能,单/双/四/精度浮点性能
Sisoftware Sandra 2017 SP1-Transcode测试——转码性能,VC1转H.264,H.264压缩
转码测试中,NVIDIA P5000一骑绝尘,速度远超越AMD显卡。

SPECviewPerf是一个专业级、符合工业标准的OpenGL图形显示卡效能测试分析软件,使用C语言编写,用于测量运行在OpenGL应用程序接口之下硬件的3D图形性能。而此次测试我们选择的是最新版的SPECviewPerf 12,其包含8个专业图形测试场景,Energy、Medical、Catia、Cero、Maya、SNX以及主要基于OpenGL 4.0架构的Solidworks和首次添加基于DirextX架构的Showcase。
CATIA-04测试的项目包括线框图、抗锯齿、着色图、轮廓线加强着色图、阴影遮蔽、景深及环境光遮蔽等,合计有14个测试子场景。测试的模型大小涵盖510万顶点到2100万顶点数量,测试结果越高越好。
Creo-01测试包含了多个PTC Creo 2支持的渲染模式,例如线框图、抗锯齿、着色图、轮廓加强着色图、着色倒影图等。测试的模型大小从2000万顶点到4800万顶点。
Energy-01重点针对的是地震、石油及天然气勘探领域的实体渲染应用,因此对工作站系统内存和显卡显存的容量需求极高(分别不低于12GB和4GB)。
Maya-04测试模型是包含72.75万顶点的电力厂场景,测试内容相当丰富,包括着色、屏幕空间蔽塞着色、屏幕空间蔽塞着色多采样抗锯齿、屏幕空间蔽塞着色多采样抗锯齿+浮点渲染对象、屏幕空间蔽塞着色多采样抗锯齿+浮点渲染对象+权重平均式半透明、线框图。
3damax-05基于3ds Max 2015软件,包含了11个建模场景,测试显卡渲染不同材质物体的性能。
Medical-01测试比较偏重纹理处理和显存带宽的压力,即考验CPU和显卡的能力。
Showcase-01基于Autodesk的Showcase 2013软件,测试用的模型顶点数量800万个,SPECviewPerf首次引入的DirectX渲染测试项目。
SNX-02测试基于Siemens NX 8.0软件,同样包含两个测试模型,模拟场景是大型装配设计和组装,测试模型顶点数量为715万到845万顶点。
SW-03测试模型规模范围从210万顶点到21000万顶点,测试包括着色图、边缘着色图、环境光吸收等测试项目。这是针对Solidworks用户而特别设计的测试。
SPECviewperf更加偏向于专业应用测试方向,所有测试成绩都是基于真实应用场景,并且一定方式给显卡运行情况进行打分,最后汇总出结果。由于测试都是跑在专业软件上,对于长期使用这类型的开发者来说,这种测试结果显然更加符合预期和真实性能。 在这个测试中,我们看到在此前测试并不占优的NVIDIA Quadro P5000成绩就发力了,大部分测试场景都能先拔头筹,领先于Radeon Vega Frontier显卡。
总结:

AMD Radeon Vega Fronier基准成绩不错,但实际应用上稍差。从前面数十个测试项目来看,AMD Radeon Vega Fronier实力不凡,在很多基准测试中,成绩都是领先于Radeon Pro Duo和Quadro P5000,从侧面上就反映了AMD对Vega架构持续深入地研究是有成效的。但是在实际测试过程中,Radeon Vega Fronier成绩与Quadro P5000还是有些差距,NVIDIA在应用上的优化还是更好一些,AMD可能就是输在了应用优化上。


游客 2018-06-02 11:49
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
17#
游客 2018-06-02 11:47
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
16#
游客 2018-03-18 07:56
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
15#
超能网友编辑 2017-08-16 11:39 | 加入黑名单
支持(0) | 反对(0) | 举报 | 回复
14#
游客 2017-08-14 22:58
已有1次举报支持(14) | 反对(0) | 举报 | 回复
13#
游客 2017-08-14 22:31
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
12#
游客 2017-08-14 21:43
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
11#
游客 2017-08-14 20:45
支持(0) | 反对(1) | 举报 | 回复
9#
超能网友终极杀人王 2017-08-14 19:40 | 加入黑名单
支持(1) | 反对(0) | 举报 | 回复
8#
超能网友教授 2017-08-14 19:01 | 加入黑名单
支持(1) | 反对(0) | 举报 | 回复
6#
游客 2017-08-14 19:00
支持(1) | 反对(0) | 举报 | 回复
5#
超能网友等待验证会员 2017-08-14 18:59 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(1) | 反对(0) | 举报 | 回复
4#
游客 2017-08-14 18:56
支持(0) | 反对(0) | 举报 | 回复
3#
我匿名了 2017-08-14 18:46
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
2#
游客 2017-08-14 18:19
该评论年代久远,荒废失修,暂不可见。
已有3次举报支持(9) | 反对(6) | 举报 | 回复
1#