Xeon Phi的实际产品要等到今年Q4季度问世,而同期还有NVIDIA先前公布过的71亿晶体管巨兽Tesla K20,后者使用GK110架构,与现有GK104专注游戏不同,GK110架构重点强化了通用计算能力,双精度浮点性能是Fermi架构的三倍之多。
Xeon Phi与Tesla K20免不了有一场对决,Intel在CPU上有NVIDIA无法企及的优势,不过在通用计算上性能要落后NVIDIA一拍,首款Xeon Phi产品有多少胜算呢,3DCenter综合了VR-Zone以及自己先前的报道将二者做了一番预估对比。
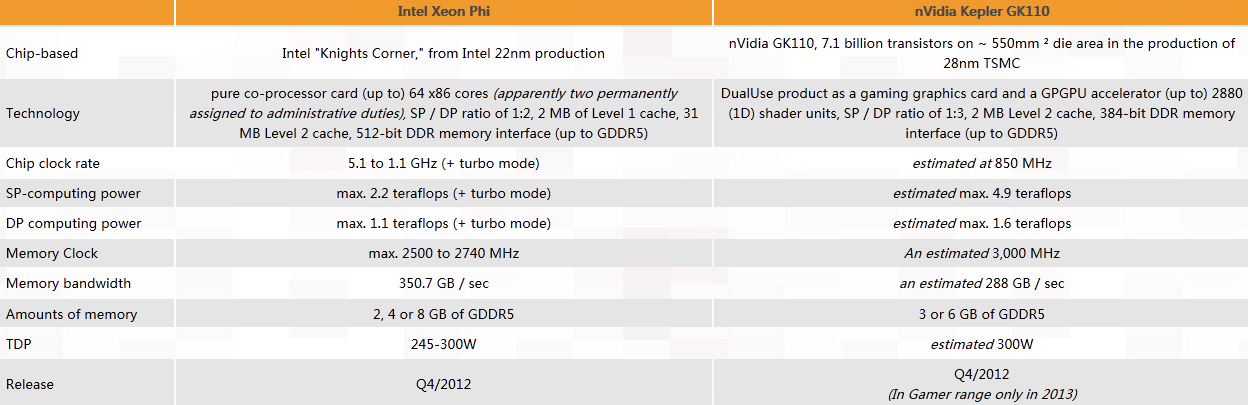
Xeon Phi与Tesla K20架构对比(点击放大)
注:Xeon Phi的频率是1.05-1.1GHz。上图中因为Google翻译导致此数据混乱了。
Xeon Phi基于通用的X86,确切地说是X64架构,将使用22nm 3D晶体管工艺,单精度:双精度效能为2:1,2MB L1缓存,31MB L2缓存,512bit GDDR5显存位宽,初期产品频率为1.05-1.1GHz,显存频率在5-5.5GHz(等效)左右,带宽350.7GB/s。
Xeon Phi使用了Intel的MIC多核架构,A0步进有48、52及60核心版本,显存频率约为2.4-4.5GHz,B0步进则有57、60及61个核心,显存频率也提高到了5-5.5GHz。
我们之前介绍过Tesla K20的架构和技术特性,它使用GK110架构,TSMC 28nm工艺,2880个CUDA核心,单精度:双精度效率为3:1,2MB L2缓存,384bit GDDR5显存,预计频率在850MHz,显存频率至少有6GHz(等效),带宽288GB/s。
单从性能上来看,K20的单精度、双精度分别是4.9TFLOPS、1.6TFLOPS,而Xeon Phi是2.2TFLOPS、1.1TFLOPS,处于下风,带宽上则略有优势。
Intel的Xeon Phi还在不断改进中,现在才是B0步进,还有时间进一步提升频率以增强双精度运算能力,毕竟Intel在制程工艺的优势是TSMC比不了的。
另外,3DCenter只分析了硬件上的规格(虽然都只是预估数值),但是软件环境上才是关键,Phi基于传统的X86架构,编程环境上有优势,再加上Intel雄厚的技术实力和金钱攻势,拉拢软件厂商的能力肯定要比NVIDIA强,最终的对决就让时间来说话吧。

游客 2012-11-01 18:52
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
7#
游客 2012-08-07 13:47
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
6#
游客 2012-08-06 12:00
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
5#
游客 2012-08-06 11:58
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
4#
游客 2012-08-06 10:26
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
3#
超能网友学前班 2012-08-06 10:09 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
2#
游客 2012-08-06 09:43
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
1#