X86处理器是英特尔发明的,长期以来在X86市场上英特尔都是有绝对优势的,最新统计显示AMD在今年Q3季度的整体CPU市场份额上首次突破10%,这统计的大概是最近几年的份额,纵观历史AMD在CPU市场上份额最高也就是20%左右,X86长期以来都是英特尔独大。双方实力一边倒的情况下,最不容易出现的现象就是弱势的一方掌握主导权,AMD赢过英特尔的一次重大胜利就是64位指令集,但在那次之后,AMD鲜有让英特尔吃瘪的时候。2007年AMD抢先英特尔推出了SSE5指令集,但是英特尔大手一挥表态不会支持SSE5,转而推出了AVX指令集,AMD之后也只能顺从,再也没无法跟英特尔争夺X86发展的话语权了。

这种情况持续了至少10年,K8之后AMD推出的K10、推土机等架构虽然不乏新意,但是制程工艺、架构设计方面的双重落伍使得AMD再也不能跟英特尔叫板,实际上过去的几年中AMD自己的生存都很成问题。去年初Zen架构的Ryzen锐龙、EPYC霄龙处理器问世,AMD的X86处理器才算重回正轨,性能也足以跟英特尔同级别处理器叫板,而多核心方面还有优势。虽然AMD的市场营销依然走的是过去多年一直在用的田忌赛马策略,但是Zen及Zen+架构的处理器整体性能上来了,再加上超高的性价比,对着AMD说“真香”的玩家也就多起来了。

锐龙一代及二代处理器大大改善了AMD的财务状态,到上个季度为止AMD已经连续5个季度实现营收增长了,可以说第一代Zen架构及改进型让AMD在X86市场上有了饭吃,而今天宣布的Zen 2架构则有可能让AMD实现更高的目标——跟英特尔争夺X86市场上的游戏规则。
上一代的推土机架构也可以说是AMD跟英特尔争X86话语权的一次尝试,可惜失败了,现在的Zen处理器再一次发起挑战,而且这两者之间还有很多相似性,比如都使用了模块化设计、都强调多核性能等等,不过二者更多的还是不同,至少Zen比推土机成功得多。
说了这么多,还是回到主题上,对于Zen 2架构我们可以简单先定个性——很可能是X86处理器规则改变者。从AMD公布的信息来看,首发Zen 2架构的Rome罗马EPYC处理器变化相当大,设计上有很多大胆创新之处,不过现在一切信息还是纸面上的,它能不能做好这个改变X86规则的处理器,现在还没有明确的结论。
Zen 2处理器首发7nm工艺:5GHz频率可期?
对CPU这种东西来说,再NB的架构也要服从于制程工艺,没有先进工艺就无从谈及性能、能效,英特尔制霸X86四十年很大程度上都是因为英特尔过去掌握着最先进的半导体工艺,特殊是在Tick-Tock周期还有效的那几年,搞的AMD疲于拼命,最终卖掉了晶圆厂,转向无晶圆半导体公司,但是代工厂Globalfoundries的32nm、28nm工艺并不成熟,直到14nm节点全套使用三星技术才算稳定下来,这也是AMD Zen处理器能够成功的一个原因。

在7nm节点,GF退出了,AMD宣布将7nm CPU/GPU芯片全部交给台积电代工,现在的Zen 2架构罗马处理器就是台积电7nm HPC高性能工艺生产的,而英特尔这几年面临着10nm工艺延期的难题,只能不断打磨14nm工艺,迄今有14nm、14nm+及14nm++三个版本了,直到明年底才有可能推出10nm处理器。
正是这个变故,让AMD在7nm Zen2处理器上实现了制程工艺优势的逆转,这也是多年来AMD首次在处理器工艺上超越英特尔。这个话题实际上早就不新鲜了,过去几个月中AMD被分析师看涨、英特尔被看衰几乎都跟AMD 7nm工艺上的领先有关。
根据AMD公布的信息,7nm工艺实现了两倍的晶体管密度、同性能下功耗降低50%或者同功耗下性能提升25%的变化,只不过这些数据还是官方纸面上的,具体情况如何呢?
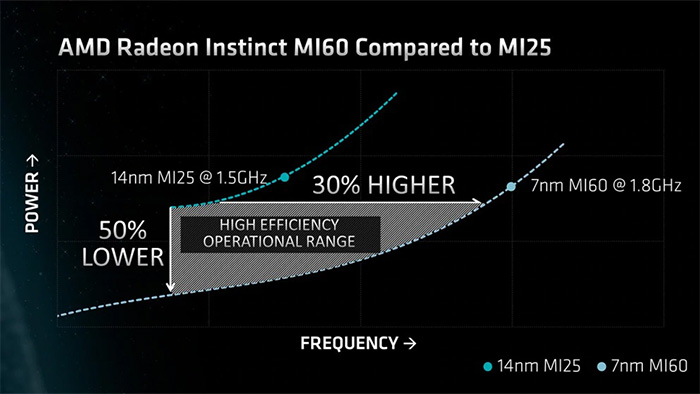
7nm Vega的工艺
Zen 2架构的罗马处理器现在没有任何具体的核心面积、频率、功耗等数据,但是AMD在7nm Vega上公布了很多具体数据——7nm Vega 20 GPU核心面积331.46mm2,晶体管数量132亿,GPU核心频率1.8GHz,显卡功率300W,而14nm工艺的Vega 10 GPU核心面积494.8mm2,晶体管125亿,GPU核心频率1.5GHz,显卡功率300W。
通过这些数据可以算出晶体管密度——14nm节点是0.2526亿/mm2,7nm节点是0.3982亿/mm2,提升不过58%而已。至于频率,同样300W功耗下,从1.5GHz提升到了1.8GHz,提升20%,基本上符合AMD所说的性能提升25%的说法。
虽然GPU跟CPU的情况不一样,但是从7nm GPU的情况来看从14nm到7nm或许可以大幅降低功耗,不过性能上的提升并不算乐观,即便真的提升了25%,考虑到7nm与14nm节点之间还隔了一个10nm节点,两代提升25%的性能并不能让人很满意。
当然,这个事也不怨AMD,元凶是摩尔定律早就失效了,只是很多人不肯承认这一点,真正意义上的摩尔定律早就不适用了,ARM早前也提到过在制程工艺进入16nm节点之后,性能已经没什么实质性提升了。

有意思的是,尽管GF已经退出了7nm节点竞赛,AMD在Zen 2架构发布的官方新闻中还是列举了GF公司的7nm工艺,与台积电7nm工艺并列。相比台积电,GF在7nm工艺上的宣传更强大一些,功耗降低60%或者性能提升40%,而且GF之前提到了高性能7nm工艺可以实现5GHz的频率,而能不能上5GHz频率正是广大A饭对AMD Zen 2处理器最大的期待。
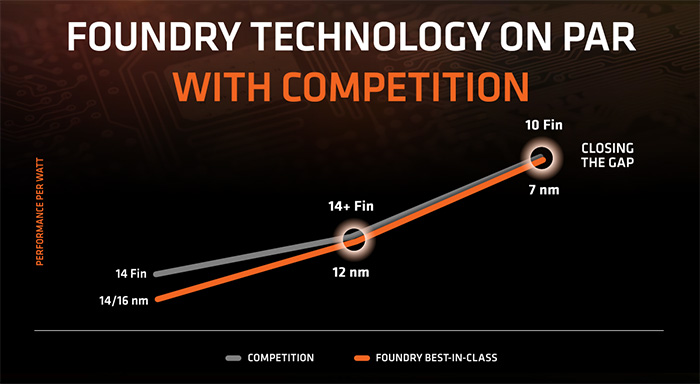
对于Zen 2架构上7nm工艺这事,AMD及A饭值得高兴,在制程工艺数字上AMD确实做到领先了,不过具体到处理器上,25%的性能提升、50%的功耗降低这些数据看看就好,因为工艺上的性能提升、功耗降低跟处理器性能、功耗并不是一回事。对于这一点,AMD自己也是心知肚明的,之前的PPT中就提到了AMD 7nm工艺与竞争对手10nm工艺的对比,AMD是缩小了差距,谈不上超越。
当然,也不能光灭AMD自己的威风,台积电的7nm工艺尽管性能不一定多厉害,但英特尔那边的10nm工艺也早就变了, 前两年展示的10nm指标上是很强大,但是量产难度也大,导致一直延期,而英特尔明年底量产的10nm工艺被曝是缩水版的,性能、功耗等指标肯定会有妥协,这对AMD来说也是好事。

即便Zen 2在工艺上无法超越英特尔的10nm,后面还有机会,因为AMD的路线图比英特尔的更快,2020年还会有Zen 3架构,制程工艺升级到7nm+,也就是上EUV工艺的7nm改良版,单纯的EUV工艺不会提升工艺性能,但台积电还会继续改良7nm+工艺,到英特尔大规模量产10nm工艺的2020年,AMD进度快的话可能会有7nm+工艺的Zen 3处理器了。
Zen 2架构改进:吞吐量翻倍,前端到浮点全线改进
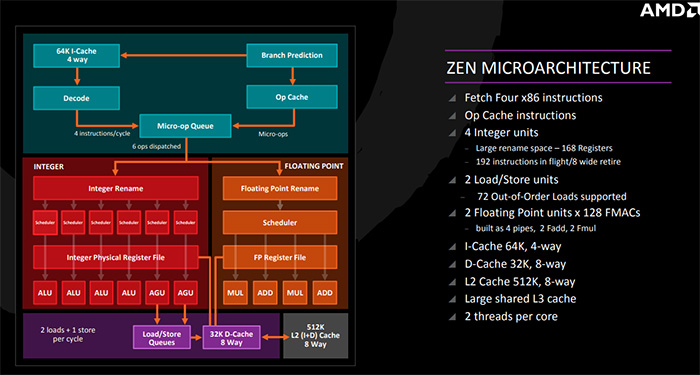
提升性能除了依赖先进工艺之外,CPU架构也是最重要的一环。在Zen架构上,AMD带来了CCX单元、SMT多线程、Infinity Fabric总线等设计,如今的Zen 2也沿用了这些设计,但在CPU内核上从前端预取单元到缓存再到浮点单元都做了改良,官方定性是实现了“吞吐量两倍”。
AMD Zen架构的CPU内核设计
AMD在官方资料中介绍了Zen 2架构在CPU内核上的改进,不过这些内容还没有具体的数据,比如L1缓存、L2缓存、L3缓存等等,所以这部分内容就简单看看官方资料,后面有了具体信息再说。

值得一提的是,浮点架构上,目前的AMD锐龙、霄龙处理器支持到了AVX2,Zen 2上AMD翻倍了浮点单元位宽,从2x128bit提升到2x256bit,但它并不支持最新的AVX512,估计要到Zen 3架构上才有可能。

架构设计上另一个值得注意的是安全——2018年让英特尔焦头烂额的一件事就是各种X86漏洞,主要包括熔断Meltown、幽灵Spectre及下半年才爆出的Foreshadow预兆,它们又衍生出多个版本。这些漏洞对英特尔处理器影响较大,熔断是英特尔独享的。虽然AMD在漏洞事件中受到的影响较小,但是Spectre幽灵漏洞是影响所有现代处理器的,因此在Zen 2架构上AMD也针对幽灵漏洞做了硬件防护。
在具体的技术指标上,Zen 2架构还支持率先支持PCIe 4.0、8通道DDR4内存等等,虽然没有DDR5内存支持,不过这样做也是很明智的商业策略了,毕竟DDR5还比较遥远。
此外,AMD表示罗马EPYC处理器相比之前的产品,能够在单路插槽上带来2x的整体性能、4倍的浮点性能,同时还能保持插槽兼容。
Zen 2最大胆的创新:8+1核架构,CPU、IO分离
AMD在7nm工艺及CPU内核上的升级、改良还是常规操作,而Zen 2处理器上最大胆的一项创新就是AMD真的做了8+1核,将CPU内核与IO核心分离出来,这种设计看起来跟近年来CPU单元整合更多I/O单元的路线相反,有利有弊,虽然AMD很有自信,但是这么大胆的设计还是让人为AMD捏了一把汗。

AMD这么改显然是为了容纳更多的CPU核心——在Zen架构中,AMD设计了CCX单元及IF总线,通过这种模块化的结构来堆砌多核处理器,桌面的8核处理器是2个CCX单元,一个模块即可,EPYC之前是32核64线程,需要4个模块。但是要想做64核,按照之前的设计就需要8个模块,而8个模块之间要是继续使用IF总线互联,那么复杂性就会大增,延迟等问题愈发严重。

AMD在Zen 2上的做法就是将IO单元与CPU核心单元分离,AMD称这种设计为Chiplets,而且CPU核心使用的工艺跟IO核心的工艺也是不同的,具体来说就是——8个CPU模块使用的是7nm工艺,每个模块有8个CPU内核,总计64个核心128线程,而IO核心是14nm工艺,整合了DDR、PCIe 4.0/3.0、Infinity Fabric等IO单元。

AMD现场展示了Zen 2架构的罗马处理器实物,就是8个CPU模块围绕1个IO核心,而且这个14nm IO核心的面积相当大,差不多要6组CPU核心那么大了——可以简单算下,锐龙8核的模块的核心面积是213mm2,前面提到实际核心面积是1.58x缩放,那么Zen 2的8核模块应该是133mm2左右,但这个核心是整合了IO单元的,纯核心简单算作100mm2吧,那么Zen 2上那个14nm IO核心面积至少是600mm2,AMD付出的代价不小。
即便如此,AMD还是这么做了,在AMD看来这个方案是64核的最优选择——目前的32核EPYC处理器核心面积是777mm2,理论上核心翻倍后面积至少1500mm2,而现在的方案中Zen 2 64核配置的核心面积也要1500mm2左右,但是分散成8+1核心显然有利于提高单品的良率,况且核心面积最大的那部分还是14nm工艺制造的,成本比7nm工艺更低。
从AMD官方的解释来看,这样的设计也是为了简化生产难度、提高良率,并且增强了CPU核心配置型,有了IO核心枢纽,以后增加CPU核心就可以只考虑CPU内核了。
AMD这种8+1核的设计最不好的地方大家也猜得到,那就是核心之间的延迟问题,锐龙/EPYC在延迟上就被人诟病了很久,现在的架构设计就更不好说了——由于缺少确切的资料,现在说它的延迟高或者低都没有证据支撑,这取决于AMD具体的设计。
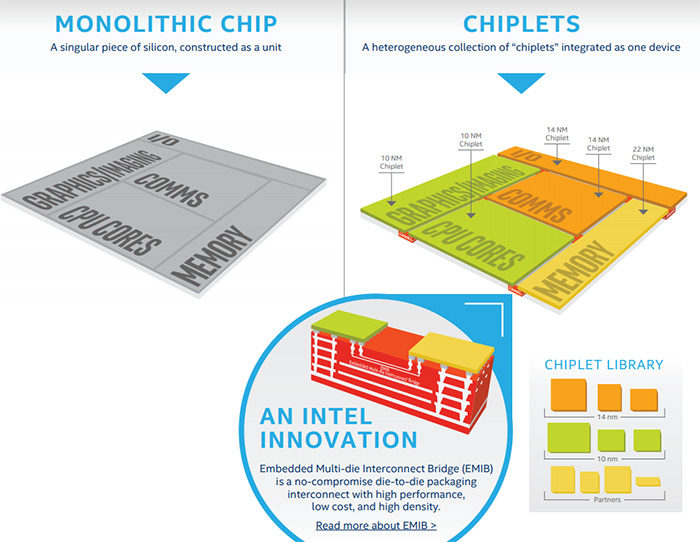
不过有一点,AMD在Zen 2上的设计不只是他们一家想到了,英特尔实际上也有这样的技术路线,那就是EMIB,其本质也是将不同的核心单元使用不同的工艺生产,然后封装到一起,这种设计看起来跟大家调侃的胶水多核很相似,但实际上英特尔的EMIB封装不同于传统的2.5D封装,在良率、制造难度及性能方面都有可取之处。
从AMD的Zen 2架构来看,AMD这一次在处理器封装技术上也实现了进步,如果能控制好外置的IO核心与CPU内核之间的延迟问题,那么这种设计未来只会越来越多。
总结:AMD不走寻常路
在金庸的《倚天屠龙记》中,九阳神功可以说是最厉害的武功之一了,该武功的口诀就是“他强由他强,清风拂山岗;他横由他横,明月照大江。”,说开了就是敌人再强就随他强,他打他的,你做你的。这句话用来形容现在的AMD再合适不过了,英特尔在CPU上有极强的积累,AMD如果照着英特尔的强项去打,那没有获胜的可能,唯一的希望就是自己主导规则,不走别人的套路。
从2017年到2018年的CPU市场竞争来看,AMD在这个策略上走对了,反而逼得英特尔跟着AMD推多核、提高性价比。在Zen 2处理器上,AMD缩小了与英特尔在制程工艺上的差距,甚至可以说“领先”一些,同时不断提升自己擅长的多核战略,英特尔也不得不跟。
上面这些都是针对EPYC处理器来说的,对普通玩家来说我们关注的依然是桌面版的Zen 2处理器,它并非本次会议的重点,所以相关信息非常少,考虑到64核处理器对桌面意义不大,所以桌面版的8-16核处理器有可能会是不一样的设计,这个就要等AMD择机公布桌面版Zen 2处理器的信息了。

游客 2018-11-07 20:21
该评论年代久远,荒废失修,暂不可见。
支持(110) | 反对(2) | 举报 | 回复
32#
超能网友终极杀人王 2018-11-07 11:26 | 加入黑名单
本评论因举报过多被折叠 [+]14#
游客 2019-05-29 10:41
已有1次举报支持(0) | 反对(2) | 举报 | 回复
66#
游客 2019-04-16 07:17
支持(4) | 反对(0) | 举报 | 回复
65#
游客 2019-03-20 12:33
支持(0) | 反对(0) | 举报 | 回复
64#
游客 2018-11-15 19:46
已有3次举报支持(5) | 反对(0) | 举报 | 回复
63#
超能网友终极杀人王 2018-11-13 23:54 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
62#
游客 2018-11-09 08:57
该评论年代久远,荒废失修,暂不可见。
已有2次举报支持(1) | 反对(0) | 举报 | 回复
61#
游客 2018-11-08 19:58
该评论年代久远,荒废失修,暂不可见。
已有3次举报支持(2) | 反对(2) | 举报 | 回复
60#
游客 2018-11-08 19:39
已有3次举报支持(6) | 反对(1) | 举报 | 回复
59#
游客 2018-11-08 18:20
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(1) | 举报 | 回复
58#
我匿名了 2018-11-08 18:04
已有8次举报支持(1) | 反对(1) | 举报 | 回复
57#
游客 2018-11-08 17:26
已有7次举报支持(1) | 反对(1) | 举报 | 回复
56#
超能网友博士 2018-11-08 16:07 | 加入黑名单
已有2次举报支持(0) | 反对(1) | 举报 | 回复
55#
游客 2018-11-08 12:17
本评论因举报过多被折叠 [+]54#
游客 2018-11-08 10:35
该评论年代久远,荒废失修,暂不可见。
已有4次举报支持(2) | 反对(0) | 举报 | 回复
53#
游客 2018-11-08 09:44
该评论年代久远,荒废失修,暂不可见。
已有2次举报支持(3) | 反对(0) | 举报 | 回复
52#
游客 2018-11-08 09:30
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(2) | 反对(0) | 举报 | 回复
51#
游客 2018-11-08 09:03
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(4) | 反对(0) | 举报 | 回复
50#
游客 2018-11-08 08:49
已有1次举报支持(1) | 反对(0) | 举报 | 回复
49#
游客 2018-11-08 08:35
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(2) | 反对(0) | 举报 | 回复
48#
游客 2018-11-08 04:47
该评论年代久远,荒废失修,暂不可见。
支持(3) | 反对(0) | 举报 | 回复
47#
超能网友一代宗师 2018-11-08 04:32 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(7) | 反对(0) | 举报 | 回复
46#
游客 2018-11-08 02:23
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(12) | 反对(1) | 举报 | 回复
45#
游客 2018-11-08 01:32
该评论年代久远,荒废失修,暂不可见。
已有6次举报支持(0) | 反对(4) | 举报 | 回复
44#
游客 2018-11-08 01:08
已有1次举报支持(17) | 反对(0) | 举报 | 回复
43#
游客 2018-11-08 01:00
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(16) | 反对(0) | 举报 | 回复
42#
超能网友终极杀人王 2018-11-07 23:15 | 加入黑名单
支持(8) | 反对(0) | 举报 | 回复
41#
游客 2018-11-07 22:46
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(13) | 反对(0) | 举报 | 回复
40#
我匿名了 2018-11-07 22:36
该评论年代久远,荒废失修,暂不可见。
支持(8) | 反对(0) | 举报 | 回复
39#
加载更多评论