NVIDIA在4月24日在深圳举行RTX AI 媒体品鉴会,邀请了众多合作伙伴与媒体来体验最新的AI应用,包括NVIDIA ACE、ChatRTX、Stable Diffusion、DLSS 3.5、NVIDIA app等现场演示Demo,还有来自土豆人tudou_man、Simon阿文、海辛、言萧等AI艺术家展示如何利用GeForce RTX 40系列AI PC创作AIGC作品,在会上NVIDIA与火星时代教育联合发布《NVIDIA TensorRT Stable Diffusion创作加速指南》,与吐司/Tensor.Art联合发布《个人用户玩转Stable Diffusion 的GPU配置推荐》。

可能还有人觉得现在AI还没什么用,但实际上AI已经在各个地方发挥了巨大的作用,在大家较为熟悉的游戏方面就有DLSS 3帧生成技术和光线重建技术,以及目前还在推进中的数字人技术——NVIDIA ACE技术Demo。在生产与创作领域AI更是发挥着更重要的作用,视频和照片编辑、图片素材生成、视频超分辨率、添加字幕以及翻译、视频会议、起草文档和PPT、数据分析和解读甚至编程等应用在AI助力下都可大幅提升效率。

其实在去年台北电脑展上NVIDIA就推出了NVIDIA ACE游戏开发版Demo,利用混合AI驱动的自然语言交互技术,为游戏中的NPC带来改变,变得更为智能,从而提高了游戏的体验。

该技术应用到游戏上其实是运用到本地以及云端相结合的混合AI模式,先是本地利用NVIDIA Riva把玩家输入的语音转化为文字,然后上传至云端的大语言模型给出对应的对话回复,接着在云端把这答复转换为语音回传本地,在本地利用NVIDIA Audio2Face为游戏角色创建脸部表情动画,让嘴型对得上声音,最后通过游戏引擎输出画面。
现场展示的Covert Protocol是Inworld AI公司与NVIDIA合作开发的一项全新NVIDIA ACE技术Demo,它突破了游戏中NPC角色互动的界限,采用多模态方法来展示NPC,将认知、感知和行为系统集成在一起,以实现身临其境的叙事效果。
在活动现场NVIDIA也展示了新版本的Chat RTX,增加了更多的功能,在新版本中它加入了对智谱AI的ChatGLM3-6B这个中文LLM的支持,同时还支持语音输入和图像搜索功能。用户用它可快速、轻松地将本地文件作为数据库连接到开放式大语言模型,快速查询与上下文相关的答案。
在本次活动上火星时代教育发布了《NVIDIA TensorRT Stable Diffusion创作加速指南》,它是为AI设计爱好者和创作者基于RTX 40系GPU提升Stable Diffusion创作效率的实操性教程。指南包括:安装与设置,加速引擎构建,加速效果对比以及NVIDIA TensorRT在实际商业创作场景的应用(海报设计、电商设计、室内效果图设计、插画设计),帮助使用者在创作过程中借助详细教程和加速工具实现商业创意落地,提升创作效率。指南由火星时代教育AI设计教研团队主要研发,NVIDIA 技术团队提供技术支持,未来将根据应用软件版本优化并迭代升级。
火星时代教育创始人王琦表示:“火星时代是NVIDIA Studio中国区生态合作伙伴,双方共同探索AI软件在设计流程中的辅助作用,并在火星影视学院部分专业引入NVIDIA Studio AI应用做教学试点,在2023年共同开发AI设计方向创作加速的公开课,此次联合发布《NVIDIA TensorRT加速Stable Diffusion创作加速指南》是火星时代和NVIDIA聚焦‘科技+教育’在设计领域的积极实践,充分激发学习者对于科技发展的关注,拥抱AI前沿技术,为个人效率加速,为商业创作赋能。”
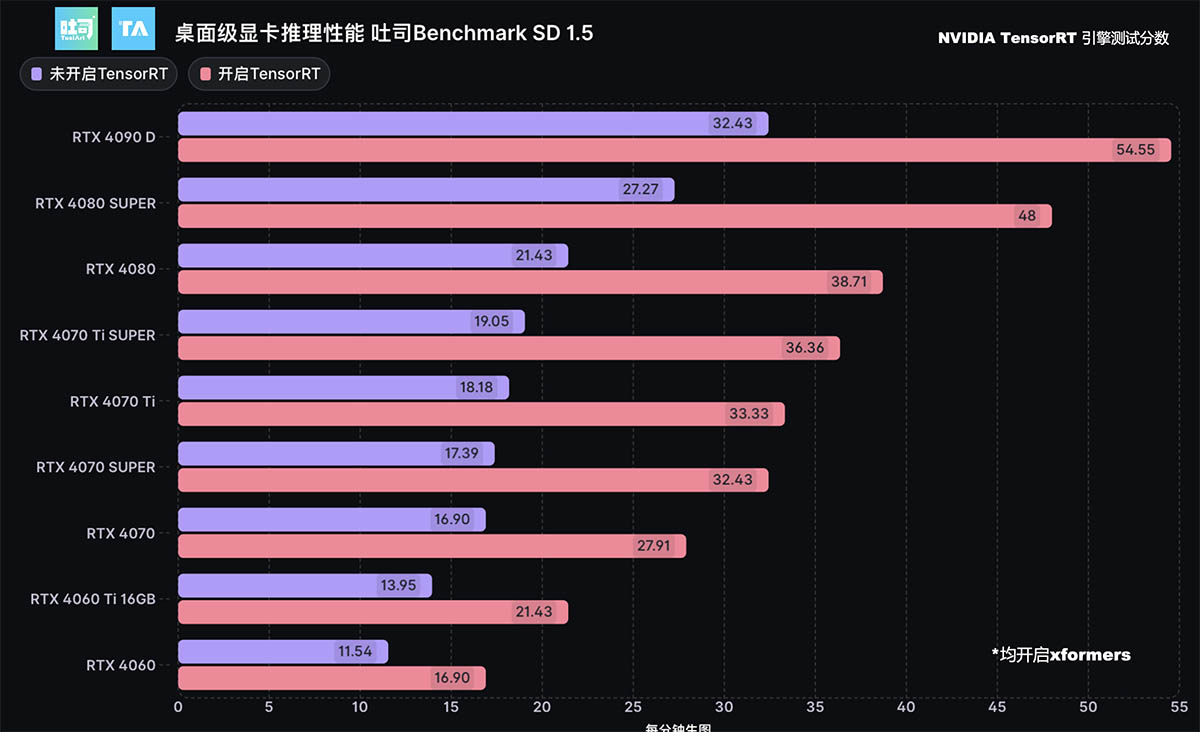
吐司/Tensor.Art在本次活动上也发布《个人用户玩转Stable Diffusion 的GPU配置推荐》,使用第三方测试软件UL Procyon AI基准测试完整测试RTX 40系列多款型号的显卡、笔记本电脑GPU在Stable Diffusion的推理性能表现,其中在UL Benchmark SD1.5 TRT vs. OpenVINO的对比测试中RTX 4090笔记本电脑GPU相对于Arc核显有超过27倍的性能提升。
使用吐司基准测试完整LoRA模型在Stable Diffusion的训练性能,还对不同型号RTX 40系显卡和笔记本电脑GPU在Stable Diffusion任务中的性能进行全面评估,旨在为AIGC爱好者在后期LoRA模型训练和设备选择时给予参考。
AI模型平台吐司/Tensor.Art 创始人沈振宇表示:“目前吐司和Tensor.Art上已经有超过16w+的模型数量。此次与英伟达联合发布《个人用户玩转Stable Diffusion 的GPU配置推荐》旨在让关注AIGC领域的入门用户以及不同垂类场景的用户在选择RTX AI PC设备进行模型训练和应用时提供客观、公正的配置参考,提升用户使用AIGC的生产效率。”
Stable Diffusion是目前最常用的AI作图工具,在现场演示Demo中,我们看到了SD专业工作流实时Demo里,在TensorRT的加持下GeForce RTX 4090 D桌面GPU可提供高达每秒8张图的生成速度。Tensor RT是当前速度最快的Stable Diffusion加速方法;目前GeForce RTX 4090 D最高能实现每秒超过百张图的生成速度,因此Stable Diffusion用户也能像游戏玩家一样通过高帧率享受丝滑的创作体验。
此外通过人像生成控制模型InstantID,用户可足不出户就能快速通过摄像头的自拍照生成高质量影棚级别的肖像照。RTX 4090笔记本电脑能为Stable Diffusion用户带来生产力级别的体验。
在建筑设计领域,即致AI基于扩散模型和蒸馏技术,通过RTX 4090 D GPU的加速,实现了秒级的AI实时绘画。结合即致AI自研的全网下载量超50W国内建筑行业大模型,帮助建筑设计师享受AI实时渲染划时代的快捷、便利的同时,依然可以保证极高的出图效果。
活动现场还有来自土豆人tudou_man、Simon阿文、海辛、言萧等AI艺术家展示如何利用RTX 40系列AI PC创作AIGC作品,由于篇幅关系这里就不一一展开了。
看完了NVIDIA展示的内容我们也想知道当前各款RTX 40系显卡在Stable Diffusion里的性能表现,回来后就跑了RTX 40系的UL Procyon AI图像生成基准测试,它使用Stable Diffusion 1.5和Stable Diffusion XL,使用一致和准确的工作负载来考验每张显卡在使用Stable Diffusion制图时的性能。
软件支持NVIDIA TensorRT、Intel OpenVINO和ONNX(含DirectML)这三个AI推理引擎,当中NVIDIA显卡可支持TensorRT和ONNX,AMD显卡支持ONNX,Intel显卡只支持OpenVINO。
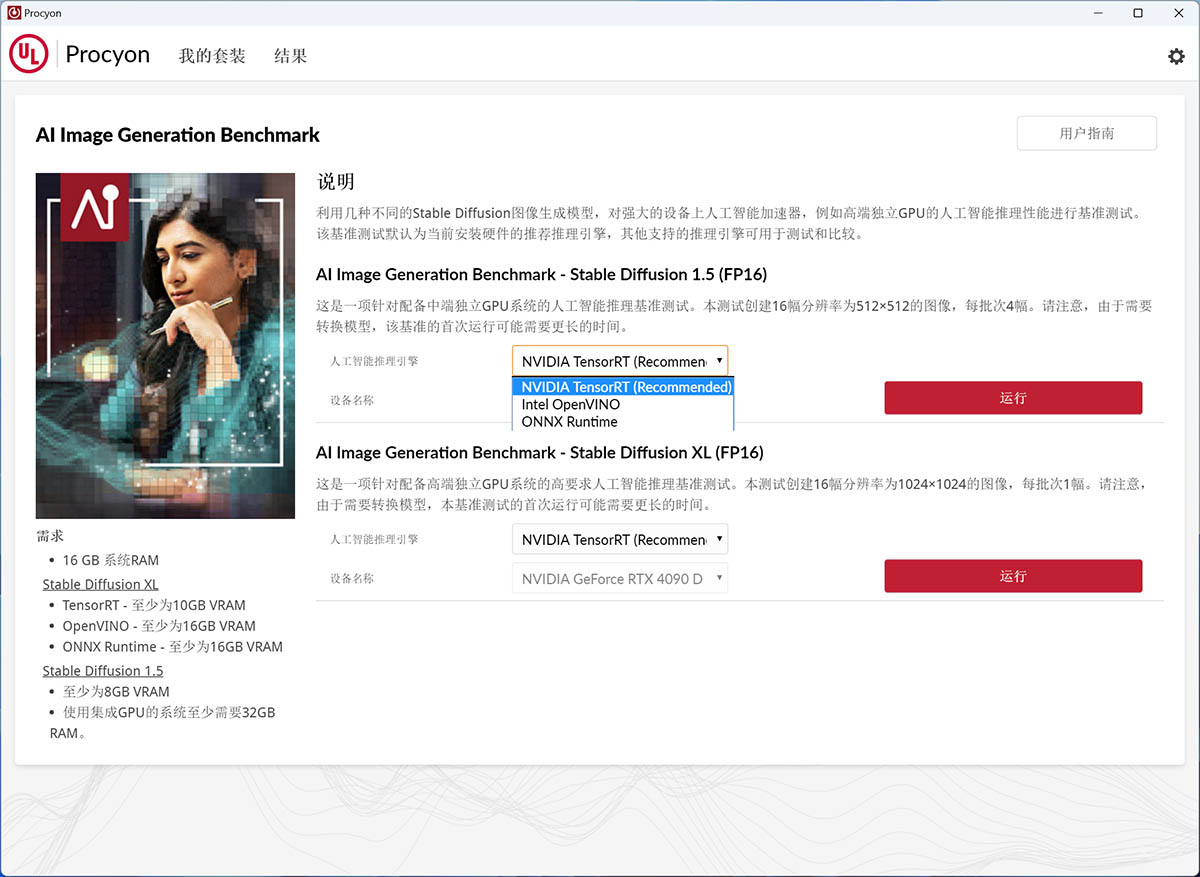
该测试对显卡的显存是有需求的,Stable Diffusion 1.5测试需要独显至少要有8GB显存,而核显系统则需要32GB内存,Stable Diffusion XL测试使用TensorRT至少需要10GB显存,使用OpenVINO和ONNX则至少要16GB显存。
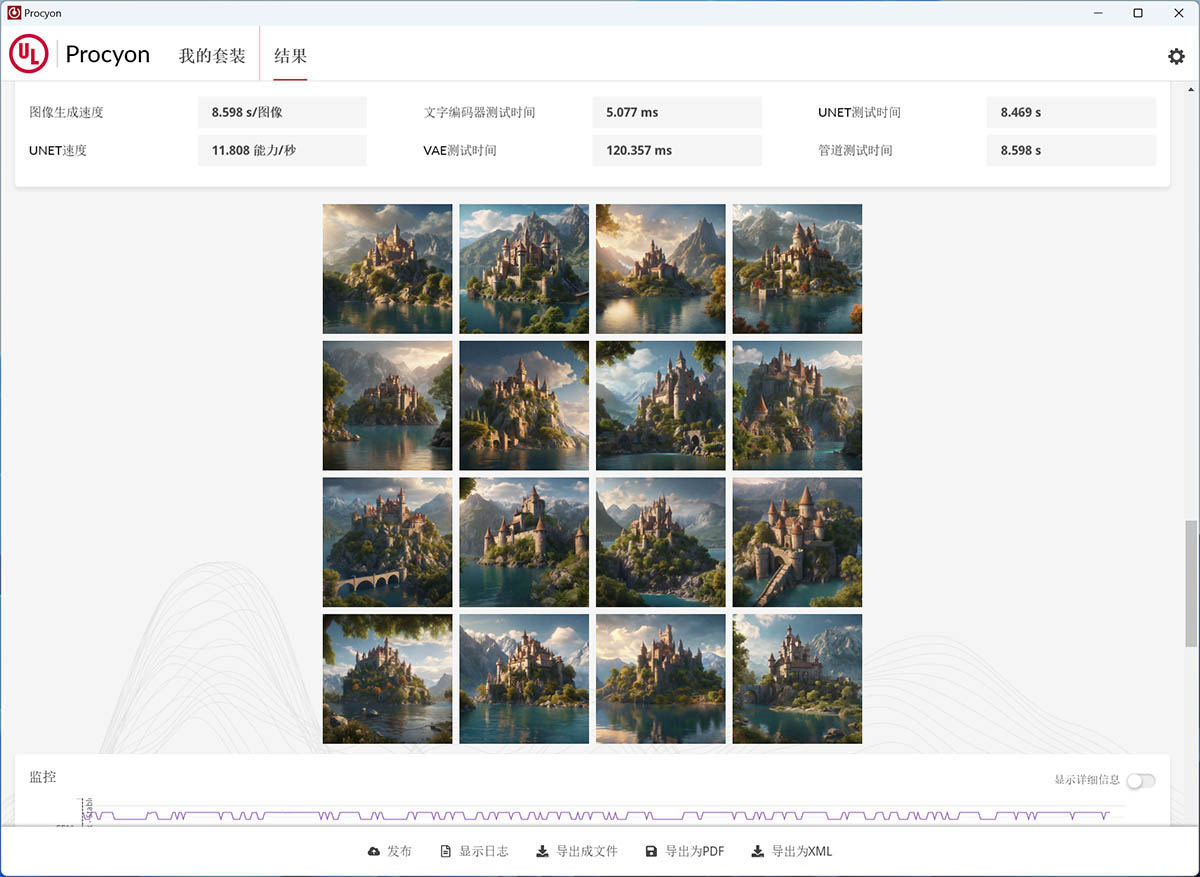
AI图像生成测试会批量生成16张100迭代步数的图片,当中Stable Diffusion 1.5测试生成的图片是512*512的,批量大小是4,而Stable Diffusion XL测试测试生成的图片则是1024*1024,批量大小是1,测完成后你可以看到这16张生成的图片,还可以点击放大。
接下来我们就用全系列NVIDIA RTX 40 GPU来跑这个AI图像生成测试,测试完成后是会给出得分、总体消耗时间以及图片的平均生成速度,根据我们观察得分和总体消耗时间是呈反比的。
先来看Stable Diffusion 1.5测试的测试结果,使用的推理引擎自然是TensorRT,得分最高的自然是性能最强的RTX 4090,为4693,而RTX 4090 D比它低5%左右,下面的卡性能落差还蛮大的,最低的RTX 4060只有1130分。
如果对得分没概念的话请看图片生成时间,RTX 4090生成一张图片只需要1.331秒,而RTX 4090/4080系列GPU生成图片时间都在2秒内,整个RTX 4070系列GPU的单张图片生成时间在2.1~3.1秒之间,到了RTX 4060 Ti生成一张图片就要4.3秒以上了,而RTX 4060更是需要5.5秒,用时是RTX 4090的四倍多。
接下来是Stable Diffusion XL的测试,这测试至少得有10GB以上的显存,所以只能从RTX 4060 Ti 16GB开始跑,得分和1.5的相比大部分都要低一些,我们直接看图片生成时间好了,图片分辨率上去后对显卡的压力大了许多,生成时间也长了许多,RTX 4090的图片生成速度是7.987秒,到了RTX 4080 SUPER就已经突破10秒一张了,RTX 4070单张耗时超过20秒,用时最长的RTX 4060 Ti达到了27.972秒。
为了让大家更好的了解这些测试结果,我们还加入了AMD RX 7900 XTX的成绩,由于它只能使用ONNX推理引擎,所以性能表现比RTX 4070还要低一点,可见两边的性能有巨大的差距。在生成式AI这方面,NVIDIA GeForce RTX 40系GPU在TensorRT的加速下性能优势还是很大的,是目前生成式AI最佳的选择,再加上NVIDIA在AI软硬件生态有相当完善的布局,所以现在数字艺术家和行业用户会选择RTX AI PC,毕竟谁不喜欢开箱即用的强劲算力呢?


旅途终极杀人王 04-29 14:43 | 加入黑名单

已有1次举报支持(5) | 反对(0) | 举报 | 回复
3#
红色的龙博士 04-28 19:57 | 加入黑名单
其实A卡用SD也不错,DML早就不用了,绘世一直用ZLCUDA,速度也可以接受的,也就热了一阵,各种CN控图、出GIF和视频,但终究不靠这个吃饭,几个月后就再也没开过了。。。游戏卡还是以游戏为重,一切看结果,像心灵杀手2,最最A卡杀手的游戏,光追方面开个基础光追(路径关掉),再配合FSR帧生成MOD版,也能稳60,画质也很好。总之还是不喜欢4060TI,性价比太低
已有4次举报支持(4) | 反对(10) | 举报 | 回复
2#
awwads大学生 04-28 18:16 | 加入黑名单
你说得对,但我很期待rtx60xx来了以后,你们还能这样夸。
已有2次举报支持(0) | 反对(2) | 举报 | 回复
1#
提示:本页有 3 个评论因未通过审核而被隐藏