事后也有很多分析,包括工艺不成熟、软件优化不足等等,最权威的解释来自Anandtech,测试分析之后认为是推土机的分支预测及指令缓存命中设计不够好,导致了架构失利。
在这之后,AMD在今年的处理器及APU上开始使用第二代推土机核心--Piledriver,号称IPC(每周期指令)性能比第一代推土机提高15%,Trinity APU所反映出来的CPU性能测试也一度带来惊喜,但是最终的结果依然是聊胜于无,变化并不大。
下一个要期待的就是第三代推土机核心-Steamroller(压路机)了,28日开幕的Hot Chips 2012会议上AMD CTO Mark Papermaster就公开了这一核心的相关信息,而Anandtech网站也做了一番解析。
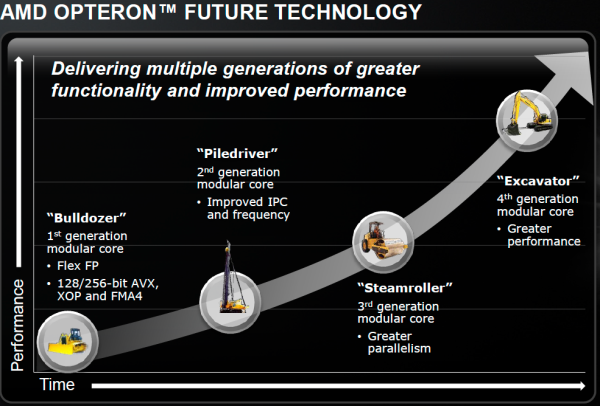
AMD处理器架构路线图
目前第二代Piledriver核心的主要变化是在功耗降低上(更可能的原因是GF的32nm SOI工艺成熟了),AMD称活动状态下平均减少10-20%,所以同样的TDP功耗下频率变高了,这一点在Trinity APU及刚刚报道过的FX-8350频率达到4GHz上可以看得出来。
Pildriver的线程调度效率也改善了,此外还有指令域取及分支预测的优化,但是总体来看性能变化并不大。
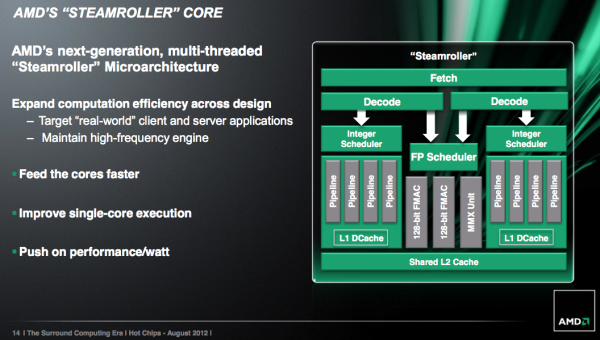
Steamroller基本沿用了Bulldozer/Piledriver的架构设计,但在他们的基础上全面进化。不过按照Intel的Tick-Tock战略来看,Steamroller并不是“Tick(指工艺升级)”,因为28nm Bulk工艺跟32nm SOI工艺没有太大区别,但是它是“Tock”架构升级,虽然大部分架构没有改变,从某些角度来看Steamroller是介于工艺转换与架构升级的两个极端中。
前端改进
推土机/Piledriver最大的问题之一就在于共享了预取和解码单元,这个问题可以从下面的表格来看:
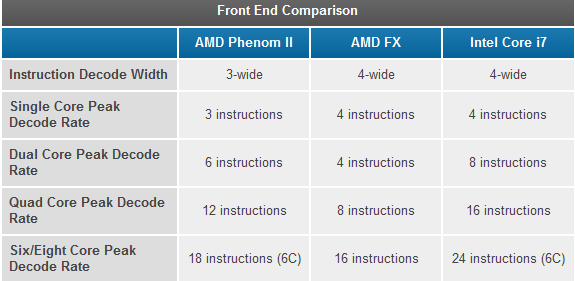
Steamroller终于改变了这个弊端,每个模块中的内核都有了自己的4发射指令解码单元,而且每个解码单元都是并行操作而非之前那种每周期循环运作。虽然双倍的解码单元并不意味着双倍的性能提升,因为4发射前端不可能总是100%利用,但它依然是Steamroller架构中最大的变化。
改用这个设计之后弊端也很明显,功耗及核心面积都要上升,但是权衡之后这么做还是值得的,而且这个不足可以从其他方面弥补,后面还会继续讲到。
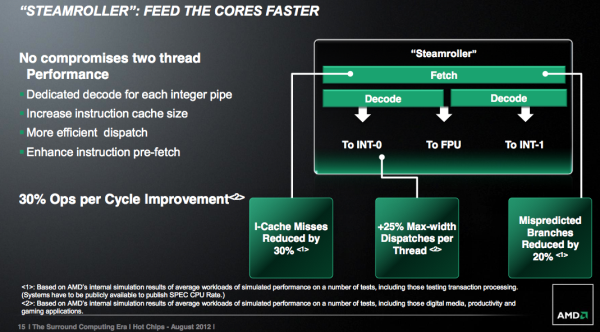
Steamroller继承了Piledriver分支预测设计,但是性能做了改进,特别是针对服务器负载,而且分支目标缓冲器更大,这样一来分支预测失败的几率就减少了20%。
执行单元的改进
AMD将Steamroller模块中的共享浮点单元更加合理化,FPU单元的执行能力并没有变化,但是核心面积总体上降低了。MMX单元现在可以与128bit FMAC管线共享部分硬件。AMD并没有提供太多介绍,只是说硬件共享只用于独有的MMX/FMA/FP操作,因此并不会带来性能惩罚问题。
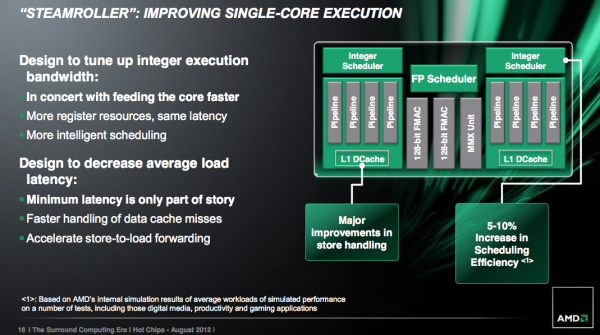
浮点单元的改进
管线资源的减少被认为是功耗和面积减少的主要原因。
整数单元的执行单元没有变化,不过其他方面的改进依然提升了它的性能。
Steamroller架构中的整数和浮点单元寄存器文件更大,虽然AMD没有明确说明有多大。负载操作(2操作)也被压缩了,因此物理寄存器文件只需要一个入口即可,这样可以提高寄存器文件的等效大小。
调度窗口(scheduling windows )的大小也提升了,这样可以更好地利用现有的执行单元资源。
存储-载入(Store to load forwarding)好像也有提升,Steamroller在侦测互锁、取消Load操作及从Store单元读取数据方面做的比前两代更好。
缓存改进
共享的L1指令缓存大小也提高了,不过AMD还是没有具体说明。推土机使用的是每模块2路64KB L1指令缓存,每个内核势能使用一路,这样一来推土机的每个内核使用的L1指令缓存就比上一代的Phenom还要少,因此Steamroller增大L1指令缓存很有意义。
AMD称增大L1容量之后,指令缓存的命中失误率降低了30%,不过有关L1数据缓存的设计没有消息。
另外,虽然AMD不愿意称之为缓存,但是Steamroller现在确实增加了一个解码微操作队列(decoded micro-op queue),一旦X86指令解码为微操作,寻址和解码操作就储存在这个队列里。预取时,只要这个队列里有对应的寻址数据,那么Steamroller的前端就会关闭解码单元,只用这个队列来服务预取请求。这与SNB架构里的decoded uop cache设计类似,当然看起来规模更小一些罢了。AMD并不愿意公开这个队列里有多少微操作,只说它们对目前的指令命中率来说已经足够大了。
L1到L2缓存的接口也提升了,队列变大,并改善了逻辑性。
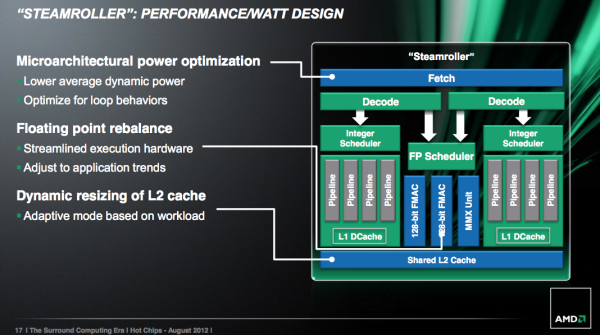
最后,Steamroller在缓存前端引入了动态大小的L2缓存,可以根据缓存负载及命中率的高低,Steamroller的模块可以1/4隔断选择使用多少L2缓存,用不到的那些就会被关闭。AMD认为这一设计在移动客户端的应用很有意义,比如视频解码时CPU只需要短时间工作而不需要太多的L2缓存应用,这一设计就可以降低功耗,提升续航时间。可调缓存不会提高性能(有一些连接延迟),它的出发点主要是减少能耗。
Steamrollerz减少L2/L3缓存延迟上没有太大变化,根据AMD的说法,他们认为推土机架构中的L3缓存延迟过高并不是问题,至少在修复上没有列入高级优先权,而且消费级市场的处理器的L3缓存通常比较少(Trinity、Llano上直接没有L3缓存),而服务器应用中对L3缓存延迟又不敏感,因此L3缓存延迟高低并没有太大意义。
未来前瞻:高密度Libraries
这部分主要讲未来的CPU设计了,而且与GPU相关,因为未来的AMD CPU设计会使用GPU那种高级自动化设计及高密度单元Libraries,简单来说就是AMD未来准备进一步使用自动化的CPU设计,更少地减少人工电路设计。
这种设计的好处是功耗和核心面积更低,在32nm推土机FPU单元上使用了这种设计之后功耗和面积减少了30%。不过缺点也不是没有,频率不够高,高度自动化的设计达不到人工电路设计的频率,不过AMD认为这也是值得付出的代价,虽然达不到最高频率,但是每个操作的功耗会降低15-30%。

Steamroller上还看不到太多高度自动化设计,不过2014年的Excavator处理器上就会看到了。
总结:
终于到总结了。
与Bulldozer、Piledriver架构相比,Steamroller更像是一次全面的进化,因为第二代核心Piledriver的目标主要是节能,而Steamroller的重点在于性能。
Steamroller的成败还要看GF明年的28nm Bulk工艺如何,纸面上的Steamroller看起来很美好,但是它还要面对Intel的Hasell处理器竞争,到时候才会有好戏看。

游客 2016-11-02 04:53
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
23#
游客 2015-10-30 08:07
支持(0) | 反对(0) | 举报 | 回复
22#
游客 2014-08-29 18:42
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
21#
游客 2014-07-19 19:26
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
20#
游客 2014-05-31 19:55
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
19#
游客 2013-09-17 00:07
该评论年代久远,荒废失修,暂不可见。
支持(5) | 反对(0) | 举报 | 回复
18#
游客 2013-02-22 19:36
该评论年代久远,荒废失修,暂不可见。
支持(1) | 反对(0) | 举报 | 回复
17#
游客 2012-09-05 16:43
该评论年代久远,荒废失修,暂不可见。
支持(1) | 反对(0) | 举报 | 回复
16#
游客 2012-08-30 21:21
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
15#
游客 2012-08-30 21:13
该评论年代久远,荒废失修,暂不可见。
支持(2) | 反对(1) | 举报 | 回复
14#
超能网友一代宗师 2012-08-30 16:27 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(0) | 反对(1) | 举报 | 回复
13#
超能网友一代宗师 2012-08-30 16:25 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(1) | 反对(0) | 举报 | 回复
12#
游客 2012-08-30 08:40
该评论年代久远,荒废失修,暂不可见。
支持(4) | 反对(0) | 举报 | 回复
11#
超能网友博士 2012-08-30 01:44 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(1) | 反对(2) | 举报 | 回复
10#
游客 2012-08-29 23:15
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
9#
游客 2012-08-29 19:53
该评论年代久远,荒废失修,暂不可见。
支持(3) | 反对(1) | 举报 | 回复
8#
游客 2012-08-29 19:16
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
7#
游客 2012-08-29 16:19
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
6#
游客 2012-08-29 16:02
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
5#
游客 2012-08-29 13:40
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
4#
游客 2012-08-29 13:01
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
3#
游客 2012-08-29 11:51
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
2#
游客 2012-08-29 11:40
该评论年代久远,荒废失修,暂不可见。
支持(1) | 反对(0) | 举报 | 回复
1#