最近RISC-V指令集架构非常受关注,这种新的开源指令集可以让处理器开发人员方便地开发出各种类型的芯片。NVIDIA很早之前就加入了RISI-V基金会,并做了很多研究。近日NVIDIA的研究人员在2019年VLSI电路研讨会上发布了一篇采用RISC-V指令集开发了一款多芯片模块式的可扩展深度神经网络加速器的论文,并在官网公布了摘要。
图片来自NVIDIA
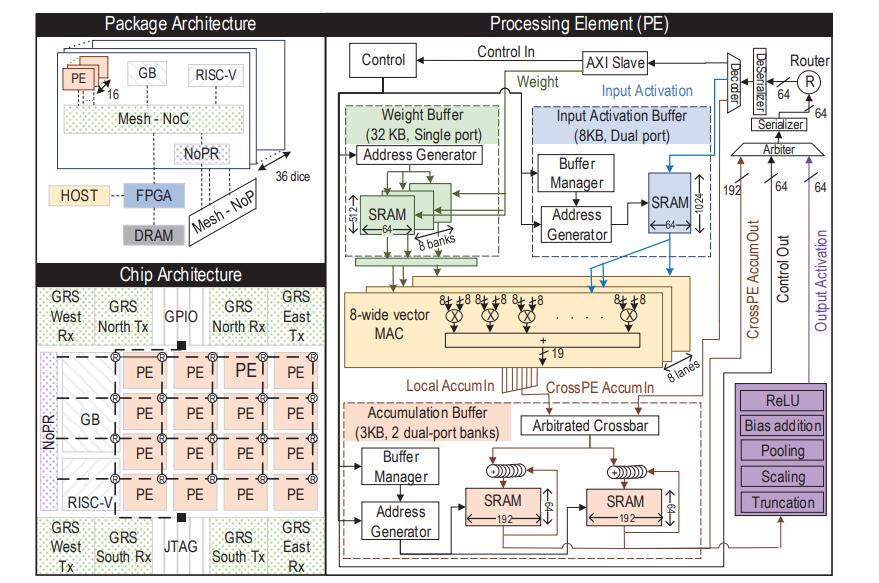
NVIDIA称深度神经网络需要高性能、运算准确以及一定的功耗要求,构建一款深度神经网络加速器通常比较难而且制造成本高。所以他们通过使用低功耗、高带宽的芯片互联技术将单个具有各种计算能力的推理加速器芯片连接起来。NVIDIA在一个芯片中集成了16个通过芯片内部网络连接的用于深度学习运算的处理元件(Processing Elements,PE)以及一个采用RISC-V指令集的控制器,而单个芯片最高可以提供4.01TOPS(每秒万亿操作),而NVIDIA的研究人员通过芯片间网络连接最高36个芯片,最高提供128TOPS的算力。

图片来自NVIDIA
除了NVIDIA公布的芯片算力外,其研究人员在论文中还提供了芯片的面积等信息。在采用台积电16nm工艺的情况下,单芯片累积核心面积为3.1平方毫米,而累积Die面积为6平方毫米,核心功耗在0.03W到4W。而36芯片(6×6规格)累积核心面积为111.6平方毫米,Die累积面积为216平方毫米,核心功耗在5W到100W之间(跨度有些大)。

图片来自NVIDIA
不过即便其多芯片互联功耗比较高,但根据NVIDIA论文中的表述,其36芯片互联最高效率达到了1.15TOPS每平方毫米,表现非常出色。但遗憾的是,NVIDIA应该没有打算推出这款芯片,仅仅是作为展示其高效能芯片设计,将来NVIDIA可能其中的设计思路融入其产品中。

超能网友一代宗师 2019-06-17 23:40 | 加入黑名单
支持(0) | 反对(0) | 举报 | 回复
5#
超能网友终极杀人王 2019-06-17 17:53 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
4#
游客 2019-06-17 16:51
支持(0) | 反对(0) | 举报 | 回复
3#
超能网友一代宗师 2019-06-17 15:45 | 加入黑名单
支持(1) | 反对(1) | 举报 | 回复
2#
游客 2019-06-17 14:07
该评论年代久远,荒废失修,暂不可见。
支持(2) | 反对(0) | 举报 | 回复
1#