GPGPU,简称通用计算技术,是一种让显卡来参与本来CPU计算任务的技术,它从提出到现在不过十余年时间,但是发展堪称神速,本期超能课堂就带大家来了解一下这项技术,并寻找在我们身边GPGPU的应用。

举个最经典的例子,在十多年前,高清视频刚流行起来的时候,当时编码高清视频对于当时的电脑来说,还是一件很困难的事情。视频编码过程中,大部分运算都是浮点类型的,而GPU对于这种类型的计算相当拿手,计算起来量又大又快,所以人们就想到,能不能利用GPU来编码高清视频。正巧当时业界的研究重点转向了GPGPU,英伟达第一个推出了一套比较完整的解决方案,将原本使用CPU的运算搬到了GPU之上,使得视频编码速度比原先快了几倍之多。如果有DIY资历比较老的读者可能还依稀记得,当时许多文章都介绍如何使用显卡加速解码蓝光视频,对于视频的编解码加速,便是最早离我们距离最近的GPGPU应用。
CPU因为有着通用性的需求,所以往往它上面单个核心会设计的非常大而全面,并且由于CPU计算的特性,核心中很大一部分面积用来构建缓存(一个核心中往往有L1和L2两级缓存)和控制单元(解码器与分支预测等前端单元),而实际用来运算的单元面积可能仅仅只占整个核心的一半甚至不到(如图)。种种原因使得CPU没有办法做非常大的规模,一个核心中能塞入的东西有限,而总体的核心数需要控制在一个合理范围中,多了就可能会发生各种各样的问题。

八核Coffee Lake的核心图,可以看到四个核心的面积已经接近右边的集成GPU
而GPU的设计理念就不一样了,本身图形计算就是一项简单而暴力的“粗活”,复杂度远不如CPU要负责的各种各样不同类型的活,想要提高图形计算速度的一个很简单的办法就是扩大处理器中含有的单元数量。所以GPU对于特定的计算任务,因为有着更大的计算单元,所以很容易就可以达到比CPU更高的计算速度,表现出来就是现在的GPU在浮点运算吞吐量上远超CPU。
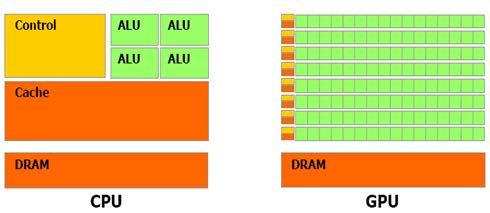
CPU与GPU在构造上的不同
因为GPU更加适合用来进行大批量特定计算的特性,几大图形软硬件厂商都纷纷推出了自己的GPGPU计算解决方案,主要有以下几种:
首先提出GPGPU实现的厂商是被收购前的ATI,并专门提供了一套开发工具包(SDK)给程序员以调用GPU来参与计算的能力。不过由于各种限制和AMD收购ATI后产生的混乱,这套SDK在与NVIDIA CUDA的竞争中处于下风,后来因为AMD官方转向支持OpenCL,这套SDK最终停止了开发。

ATI Stream Logo
CUDA是NVIDIA在G80时代推出的一项技术,全称Compute Unified Device Architechture,统一计算架构。从G80那代核心开始,NVIDIA率先采用了一种统一设计的架构,将原本的管线分工式设计转变为统一化的处理器设计。CUDA就伴随着G80核心的发布一起公之于众,这套平台可以让程序员用C和C++来编写用GPU运行的程序,学习成本比ATI Stream要低一些。
![]()
NVIDIACUDA Logo
CUDA也是目前应用最为广泛的一种GPGPU实现,在NVIDIA的强力推广之下,CUDA在许多领域大放异彩。
上面两个GPGPU的实现都是有平台针对性的,要想用他们的解决方案你就得用他们家的硬件,而OpenCL就不一样了。
OpenCL最早是一组由苹果公司开发出来的用于异构计算的框架,苹果公司将这套框架的草案提交到Khronos组织,作为一种开放标准供业界使用。在2008年末,1.0版本正式公开,目前Intel、AMD与NVIDIA的GPU都支持这套框架。
![]()
OpenCL Logo
不过OpenCL并不仅限于在x86平台上面提供异构计算的框架,由于跨平台和开放标注的特性,它还可以使用专门的可编程电路来加速计算。所以业界对于它的支持非常广泛,下图就是OpenCL联盟成员。

OpenCL联盟
DirectCompute是微软从DirectX 10开始加入的用于通用计算目的的API集,可以调用GPU进行加速计算。从Vista开始,Windows的各种桌面特效就开始采用DirectCompute来加速计算。在DirectX 11中,微软完善了这套API,并且在Windows系统上更多地使用GPU来加速计算系统界面的各种特效。
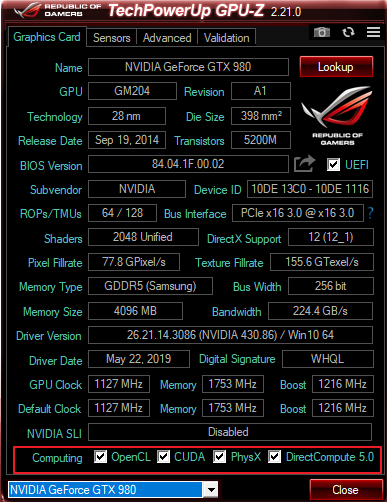
GPU-Z显示该GPU支持的通用计算特性
在十年多以前,H.264等面向高清应用的视频编码格式刚流行起来的时候,因为CPU的性能限制,编码一段H.264的视频是一件相当耗费时间的事情,所以人们想到了用GPU来加速视频的编码。NVIDIA刚推出CUDA的时候,就将加速视频编码作为该技术的一大卖点来宣传,并免费提供了一个支持CUDA技术来转码的软件BadaBoom。不过后来,NVIDIA在显卡上加入了专门用于视频编解码的硬件电路,并开放了名为NVENC的编码API供软件调用,通用计算也就此离开了这个可以说是最早利用它,也是离我们最近的领域。
BadaBoom加速视频转码
Adobe也很早就在旗下的CS和CC系列软件中加入了GPGPU的支持,比如Premiere Pro和After Effect都支持OpenCL来加速视频的实时预览和特效。
在英伟达、英特尔和AMD三家相继在自己的GPU中加入专用计算电路用以加速编解码视频之后,通用计算就离开了这个领域。但是有些不满足于既有的视频品质的人们又开发出了新的可以利用GPGPU的功能:视频补帧。
视频补帧指的是在原本低帧数的视频,通过上下帧的计算,渲染出一帧原本不存在的画面补在两帧之间,使其观感更加流畅。比如将24帧的视频补帧至60帧,因为这个过程的计算量过于庞大,使用CPU跟不上视频播放的速度,没法做到实时补帧,所以开发者就将这个功能搬到了GPU上来运行,比如很多人都在用的SVP4,就是一个利用GPGPU的补帧软件。
SVP4补帧软件界面
在视频画面优化领域,目前地球上最强的视频渲染器MadVR也是利用GPGPU来优化视频画面表现,比如视频播放中出现的色带、色环,还有在压制过程中出现的瑕疵等,都可以使用GPGPU在视频的播放过程中进行实时的弥补。
人工智能与深度学习是近年来非常热门的两个有关联的领域,训练人工智能需要非常大的数据计算量,这时候就可以利用上GPU的特长,比如热门的深度学习框架TensorFlow就可以使用CUDA来加速学习。
NVIDIA在这两年也不断展示了他们在机器学习方面的一些结果,比如在RTX系列上引入的DLSS(深度学习抗锯齿)技术就是利用机器学习来达成的。

DLSS技术

科研领域的应用
上图是CUDA在科研领域的一些应用,可以看到GPU确实在很多方面开始默默影响着我们的生活。
老黄从G80开始就一直同步推出同架构的纯计算卡,归于Tesla品牌之下。于是就诞生了很多用Tesla计算卡来组建的超级计算机,比如竞争贝尔·戈登奖的六个入围者中,有五个使用了由NVIDIA GPU提供支持的超级计算机。最近英伟达还联手ARM,在超级计算机领域中继续发力,预计未来采用GPGPU技术的超级计算机将会越来越多。

Tesla V100加速模块
GPGPU这个相对于PC整个历史还算是比较新的概念,经过十余年的发展已经不仅局限于PC,还走向了其他领域,扎根于我们生活的每个角落。GPGPU已经在许多云计算平台上得到了应用,相信在以后,GPU会更加深入我们电子生活的方方面面,在那里默默地发热。


游客 2019-07-05 13:10
支持(2) | 反对(0) | 举报 | 回复
9#
超能网友终极杀人王 2019-07-04 23:15 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有9次举报支持(1) | 反对(10) | 举报 | 回复
8#
游客 2019-07-04 21:42
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
7#
我匿名了 2019-07-04 21:03
支持(10) | 反对(0) | 举报 | 回复
6#
我匿名了 2019-07-04 20:17
已有1次举报支持(4) | 反对(1) | 举报 | 回复
5#
我匿名了 2019-07-04 20:10
支持(2) | 反对(0) | 举报 | 回复
4#
我匿名了 2019-07-04 19:26
支持(2) | 反对(1) | 举报 | 回复
3#
超能网友终极杀人王 2019-07-04 19:24 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(4) | 反对(0) | 举报 | 回复
2#
超能网友终极杀人王 2019-07-04 19:05 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
1#