经过了多年的发展,GPU也具备了多层缓存的结构。这些精心设计的缓存架构,可以填补显存和计算单元之间读写速度不匹配的矛盾,与CPU的缓存有类似的作用。

由于GPU架构的不同,不同芯片设计厂商对其缓存的设计也不一样。在Ampere架构上,英伟达仍然坚持使用相对传统的L1和L2缓存两级结构。AMD在RDNA 2架构上,则采用了L0、L1、L2和Infinity Cache,事实上Infinity Cache是充当了L3缓存的角色。近期Chips and Cheese发布了一项新研究,比较了英伟达与AMD最新显卡的显存延迟情况。
Chips and Cheese采用了OpenCL编写的指针追踪基准,用于评估GPU显存缓存中的延迟。在测试里,使用的是Radeon RX 6800 XT和GeForce RTX 3090显卡。测试结果表明,RDNA 2架构比Ampere架构具有更低的显存延迟。
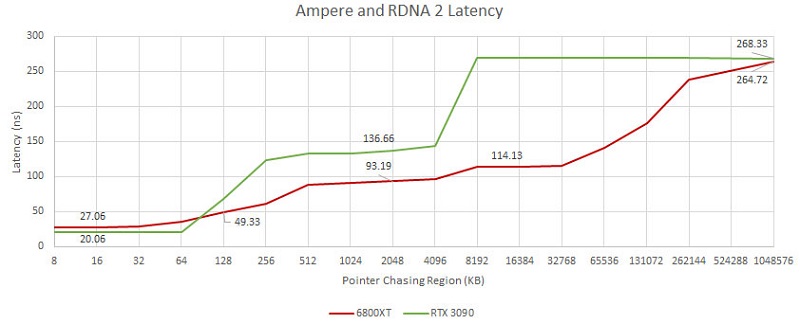
在测试中,英伟达GA102的L1和L2缓存之间的延迟超过了100ns,而AMD Navi 21的L0至L2缓存之间的延迟为66ns,加上Infinity Cache仅增加了20ns的额外延迟。这可能可以解释为什么RDNA 2架构在较低分辨率的时候会有更出色的性能表现,而Ampere架构需要更多并行运算才能有更好的发挥。
无论英伟达还是AMD,都注意到了大型高效缓存的重要性。英伟达GA100(Ampere)的L2缓存已经增加到了40MB,是GV100(Volta)的七倍。AMD则率先使用了高带宽的设计,类似的结构也有用于CDNA架构的Instinct系列,在Radeon RX系列中(RDNA)为游戏开发了Infinity Cache。
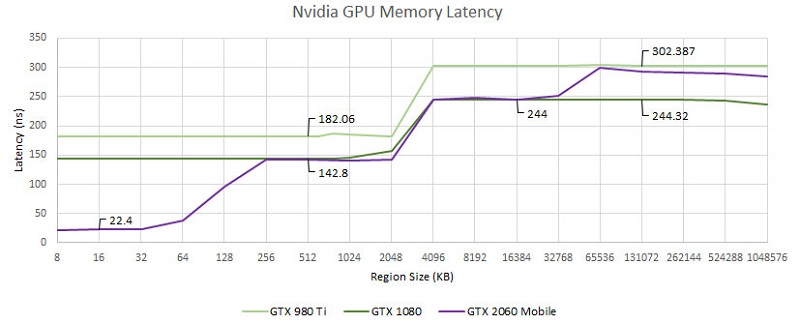
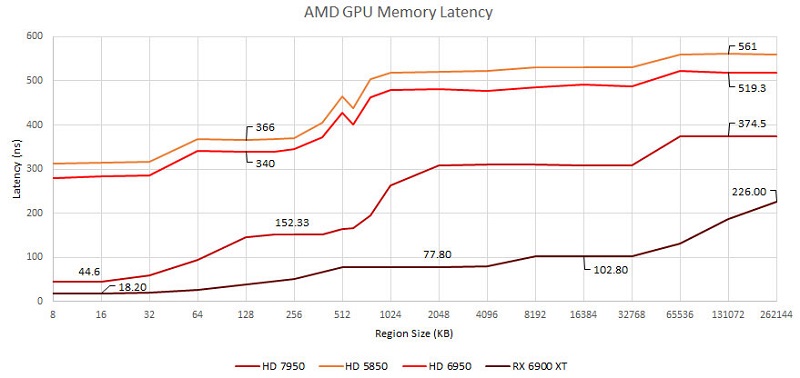
Chips and Cheese还比较了英伟达和AMD较老的一些架构,总体而言都在不断改善。不过AMD每一代架构都随有一定程度的降低,相对来说更明显。


超能网友终极杀人王 2021-04-20 21:49 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(0) | 反对(3) | 举报 | 回复
5#
超能网友教授 2021-04-20 13:42 | 加入黑名单
支持(5) | 反对(0) | 举报 | 回复
4#
超能网友博士 2021-04-20 11:42 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(1) | 反对(1) | 举报 | 回复
3#
我匿名了 2021-04-20 10:47
支持(3) | 反对(0) | 举报 | 回复
2#
超能网友终极杀人王 2021-04-20 10:31 | 加入黑名单
1#
提示:本页有 1 个评论因未通过审核而被隐藏