近日,国外有玩家突破了AMD官方的限制,成功将AMD RX 5700 XT显卡超频过了2.2GHz,在古墓丽影暗影的测试中成绩摸到了NVIDIA RTX 2080的屁股。

图片来源Tom's Hardware DE,下同
在Radeon RX 5700系列首发评测文章中,我们对这两张公版显卡进行了超频测试,结果表明这两张卡留有比较大的超频空间。AMD显卡的超频可以很容易的使用官方驱动面板中的WattMan来完成,而官方对于每张卡在系统中也预留了一个叫做SoftPowerPlayTable(以下简称SPPT)的表,描述了卡的频率上限、功耗上限以及电压设置。正确地修改这张表就可以获得突破官方限制的能力,能够挖掘显卡更深的性能极限。
igorsLAB首先研究清楚了官方对于Navi显卡的功耗调节机制,与之前的A卡一样,显卡的BIOS中存放了一份PowerPlay(A卡的节能技术)信息,驱动程序会读取这些信息,并将其保存在注册表中。简单的对注册表进行修改就可以获得突破官方限制的能力,甚至不用改BIOS。
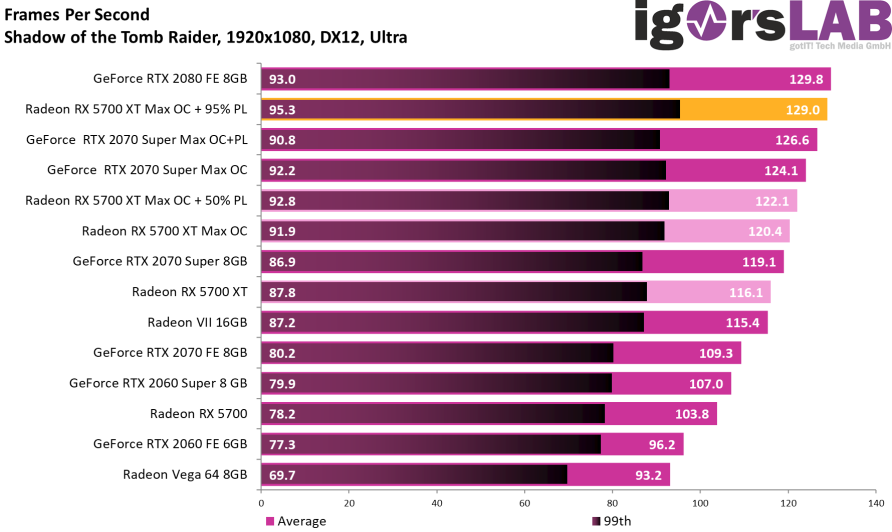
在正确地修改了注册表中的SPPT信息之后,他们对显卡进行了超频后的游戏测试,不过只做了一款古墓丽影暗影的测试,结果是惊人的,5700 XT提升最大功耗和极限超频的情况下,平均帧数已经摸到了RTX 2080 FE的屁股了,甚至在99th帧数上已经赢了。
不过此时的功耗也达到了一个很高的地步:250W,已经比最大超频的RTX 2070 SUPER高了30W左右了。
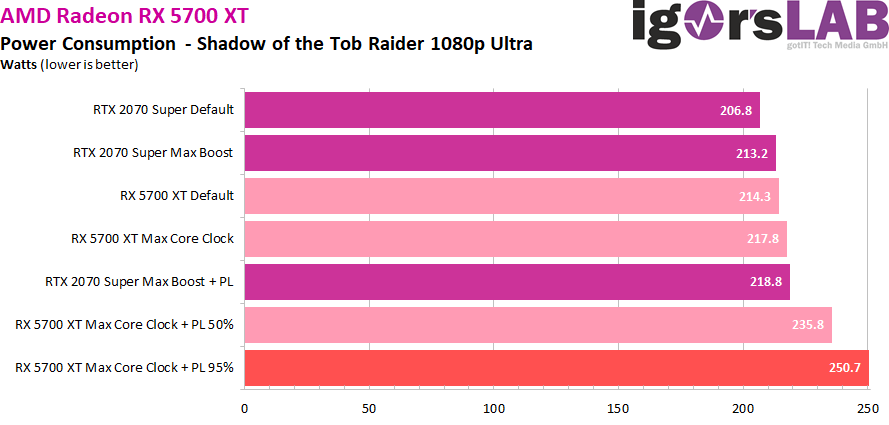
这次测试结果表明公版RX 5700 XT在核心频率的设定上还是比较保守的,相对于默认的1605MHz,Boost后的1905Mhz,起码还有200MHz的空间可以拉,部分体质好的核心可能可以拉到2.2GHz以上。也说明了目前7nm工艺在生产大芯片方面可能仍然处于一个爬坡期,可能是芯片体质差异较大的原因,AMD将默认频率设定在一个比较低的水平来保持总体的稳定。而非公版上市较晚的原因,也可能是在等待工艺的稳定,这也更加让人期待起非公版的RX 5700 XT到底有多能超了。


超能网友大学生 2019-07-14 18:16 | 加入黑名单
11#
我匿名了 2019-07-27 08:49
支持(1) | 反对(1) | 举报 | 回复
74#
游客 2019-07-23 20:45
该评论年代久远,荒废失修,暂不可见。
支持(1) | 反对(0) | 举报 | 回复
73#
超能网友教授 2019-07-17 23:14 | 加入黑名单
支持(0) | 反对(0) | 举报 | 回复
72#
游客 2019-07-17 23:11
支持(0) | 反对(0) | 举报 | 回复
71#
游客 2019-07-17 09:08
支持(0) | 反对(0) | 举报 | 回复
70#
超能网友研究生 2019-07-17 08:30 | 加入黑名单
支持(4) | 反对(0) | 举报 | 回复
69#
超能网友一代宗师 2019-07-16 13:40 | 加入黑名单
已有7次举报支持(4) | 反对(9) | 举报 | 回复
68#
超能网友博士 2019-07-16 10:41 | 加入黑名单
支持(0) | 反对(0) | 举报 | 回复
67#
超能网友教授 2019-07-16 09:08 | 加入黑名单
支持(2) | 反对(0) | 举报 | 回复
66#
超能网友一代宗师 2019-07-15 23:29 | 加入黑名单
已有4次举报支持(0) | 反对(5) | 举报 | 回复
65#
游客 2019-07-15 23:26
已有6次举报支持(0) | 反对(6) | 举报 | 回复
64#
超能网友教授 2019-07-15 23:09 | 加入黑名单
支持(0) | 反对(0) | 举报 | 回复
63#
超能网友教授 2019-07-15 23:05 | 加入黑名单
支持(5) | 反对(1) | 举报 | 回复
62#
超能网友一代宗师 2019-07-15 21:32 | 加入黑名单
已有8次举报支持(1) | 反对(8) | 举报 | 回复
61#
超能网友一代宗师 2019-07-15 21:28 | 加入黑名单
已有5次举报支持(1) | 反对(5) | 举报 | 回复
60#
我匿名了 2019-07-15 21:23
支持(1) | 反对(0) | 举报 | 回复
59#
我匿名了 2019-07-15 21:22
支持(1) | 反对(0) | 举报 | 回复
58#
游客 2019-07-15 20:45
支持(6) | 反对(1) | 举报 | 回复
57#
超能网友教授 2019-07-15 20:39 | 加入黑名单
已有1次举报支持(7) | 反对(1) | 举报 | 回复
56#
超能网友教授 2019-07-15 19:20 | 加入黑名单
支持(0) | 反对(0) | 举报 | 回复
55#
我匿名了 2019-07-15 18:46
已有10次举报支持(2) | 反对(12) | 举报 | 回复
54#
超能网友教授 2019-07-15 18:13 | 加入黑名单
支持(3) | 反对(1) | 举报 | 回复
53#
超能网友教授 2019-07-15 18:12 | 加入黑名单
支持(12) | 反对(1) | 举报 | 回复
52#
超能网友教授 2019-07-15 17:56 | 加入黑名单
已有3次举报支持(8) | 反对(6) | 举报 | 回复
51#
我匿名了 2019-07-15 17:40
已有1次举报支持(6) | 反对(2) | 举报 | 回复
50#
超能网友博士 2019-07-15 17:05 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(2) | 反对(1) | 举报 | 回复
49#
游客 2019-07-15 17:02
支持(0) | 反对(0) | 举报 | 回复
48#
游客 2019-07-15 16:23
已有1次举报支持(2) | 反对(2) | 举报 | 回复
47#
游客 2019-07-15 16:16
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
46#
提示:本页有 1 个评论因未通过审核而被隐藏
加载更多评论