很多读者朋友可能在阅读我们的文章时经常会看到AVX指令集这个名词,比如说在CPU评测中就往往能够看到它的身影,一些新入坑的玩家可能会不明白这个名词的含义,今天这篇文章就简单介绍一下该指令集的来龙去脉,并且梳理一下它目前在实际中的应用情况。
要搞明白AVX指令集的作用,首先要讲明白它是什么。定义很简单,它就是x86处理器上面的一套SIMD指令集,是经典的SSE系列指令集的直接继承者。那么SIMD又是什么呢?
在计算机刚刚出现的早期阶段,冯·诺伊曼式计算机每次输入一个指令只能够操作一对数据,比如说"+,a,b"可以让ab进行相加,这就是单指令流单数据流(Single Instruction Stream, Single Data Stream)。显然,在面对大量数据的时候,这种操作数据的方法效率较低,程序员想要让一次操作就对多组数据生效,怎么办呢?单指令流多数据流操作(Single Instruction Stream, Multiple Data Stream)的思路就被引入了,它让输入一次指令就操作多组数据变成了可能。
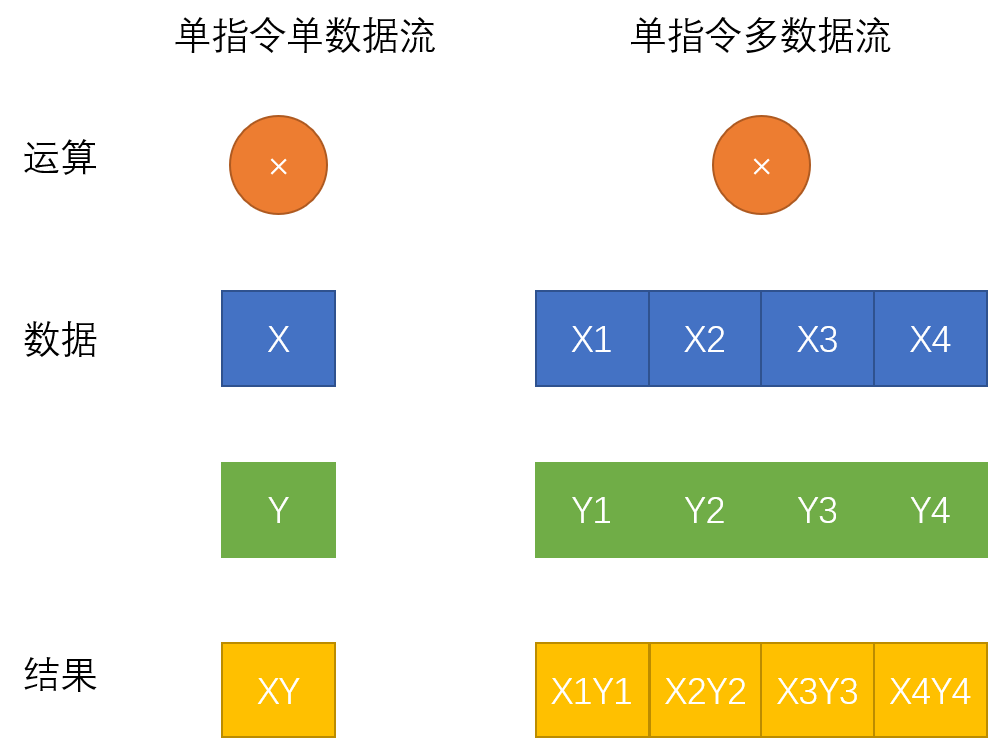
更直观的区别可以看上面的示意图。
上世纪八九十年代,很多处理器开发商都意识到了SIMD的前景,他们开始往自家的处理器里加入SIMD支持。1996年,Intel发布了基于新版P55C架构(最早一版Pentium处理器为P5架构)的Pentium MMX系列处理器,其中引入了新的MMX指令集,开始支持SIMD。
![]()
Pentium MMX系列处理器上新引入的MMX指令集开创了x86处理器支持SIMD操作的先河,该指令集定义了8个64-bit宽度的寄存器,每个寄存器的64-bit容量中可以放入八个8-bit长度的整数或四个16-bit长度整数或两个32-bit整数,CPU在识别到MMX指令集的新指令时会自动将寄存器中的数据进行分割计算,这样一来,单个指令就成功操作了多个数据,实现了SIMD。
但MMX毕竟太嫩,它实际上是通过复用CPU内部x87浮点单元的寄存器来实现SIMD的,所以与运行浮点运算的x87指令集有冲突,两者不能交叉使用,必须先进行切换。另外,由于上述的冲突,它只支持整数操作,在即将要到来的3D时代中显得有些不够用。
Intel当然很清楚MMX指令集的局限之处,而竞争对手新捣鼓出来的3DNow!指令集(1998年,AMD K6-2)已经支持了浮点SIMD运算,于是他们赶紧在经典的奔3处理器上面引入了新的SSE(Streaming SIMD Extensions)指令集,时间点为1999年2月份。
SSE指令集解决了MMX指令集身上存在的两大问题,通过引入新的独立寄存器解决了与浮点运算间的冲突问题,同时也就支持了浮点SIMD运算。当然它相对于MMX有很大加强,表现在它的寄存器宽度随着处理器架构的进步而达到了128-bit,这样一来一次SIMD指令能够操作更多的数据,效率上有大幅度的提高。不过初代SSE指令集的单个寄存器只支持32-bit长度的浮点数,还是有很大的局限性,这个问题在Pentium 4(Willamette,2000年)上面引入的SSE2中被解决了,SIMD操作的灵活度高了很多。
随后在约莫8年的时间里,Intel一直在更新SSE指令集,从SSE出到SSE4,AMD方面则是一直在跟进,到了SSE4.2,AMD开始想要在指令集上面寻找自己的翻身点,于是推出了只有自家支持的SSE4a子集,随后更是提前于Intel提出了SSE5。
但Intel不干,我是x86的老大,我不能跟着你来。他们另起炉灶,准备在未来的Sandy Bridge架构中引入一套新的SIMD指令集,这套新指令集在2008年公布,被命名为高级向量扩展(Advanced Vector Extensions)。
相比起迭代了多年的SSE系列指令集,AVX指令集带来了巨大的革新,其中最为主要的是,它在兼容SSE指令集性的同时,将SSE时代最大宽度为128-bit的寄存器拓宽到了256-bit。
不过初代AVX指令集还是比较保守的,它没有将所有指令宽度拓宽到256-bit,而是选择停留在128-bit上面。全面进入256-bit时代这个任务,还是交给了随后的Haswell架构来完成(2013年6月份)。

同处理器用不同指令集的能效对比
但如果以为Intel会就此停下脚步的话,那就大错特错了,他们很快捣鼓出了更宽的AVX-512指令集,顾名思义,其寄存器宽度再次加倍,来到512-bit。
首个支持AVX-512指令集的处理器其实是Intel的Xeon Phi加速卡,首次跑到CPU上已经是Skylake-X系列了。而AVX-512也并不再是一个单一的指令集,它实际上指代的是多个指令集的集合,目前这个数字是17,之后可能还会增多。所有支持AVX-512的处理器都必须支持AVX-512 Foundation子集,从命名上也可以看出,它其实是AVX-512指令集的基础。
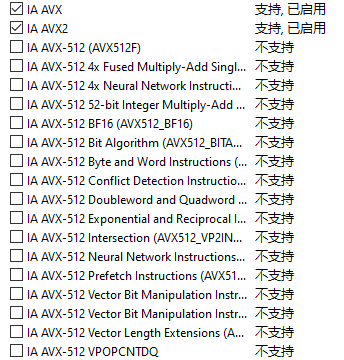
长长的AVX-512子集列表
目前只有基于Skylake-Server和Ice Lake这两个架构的处理器可以支持AVX-512(Cannon Lake死了,不然也算),使用门槛较高,一般新一点的应用也只是针对AVX2进行优化。
宽度越大,处理器的计算能力也就越强,尤其是在浮点运算方面,理论上提升有一倍之多,而实际应用中,如果优化得当,其提升幅度还要大一些。但是,新指令集在带来性能增长的同时也带来了另一个让人感到头痛的问题——功耗。
AVX指令集在带来更高性能的同时让CPU的峰值功耗也变高了,可以通过下面的例子进行理解:
飞机发动机是按照最大起飞重量设计的,如果实际的载重没有到最大起飞重量的话,飞行员就可以减推力起飞来降低油耗。CPU也是一样的,最吃功耗的执行单元是根据最大宽度来设计的,平时用不到最大宽度的时候它的功耗就小了,而一旦用到极限,它也就会全开,此时CPU的功耗就上去了。
Intel AVX is Designed to achieve higher throughput for certain integer and floating-point operations. Using these instructions may cause processors to operate at less than the marked TDP frequency. These reductions in frequency occur because high-power Intel AVX instructions require additional voltage and electrical current.
现如今CPU的功耗是根据负载大小来的,在同频下面,AVX2的负载明显高于SSE负载,因此它的功耗也会大上去。为了让CPU的功耗保持在TDP范围之内,Intel特地设计了一个AVX偏移频率,让工作在AVX状态下面的处理器降低一点频率以减小发热量和功耗,保证使用安全。Intel官方也在2014年的一份AVX指令集优化白皮书中明确说明使用AVX指令集需要额外的电压和电流。
对于我们这些要做跑分评测的编辑来说,最常接触到的AVX应用其实就是AIDA64了,那么可能有读者就要问了,这个指令集都已经推出十年了难道只能用来跑分烤机吗?当然不是,在Intel的推广之下,现如今已经有大量的生产力应用支持它了,主要在渲染、视频编码、加解密和数学计算等方面有应用,新的AVX-512还针对深度学习推出了AVX-512 VNNI子集,另外,普通玩家最为关心的游戏方面也是有越来越多的应用了,下面举几个例子。
渲染方面最常见的有Blender,它不仅仅在我们的测试中被用的多,是真的有很多人都会用它做动画或者CG图,它的渲染引擎可以调用AVX2指令集进行加速计算,吃满你的CPU。
跟渲染方面有点搭边的就是视频编码了,x264和x265这两个知名开源视频编码器想必已经不用再多介绍了,它们都在前几年中纷纷加入了对于AVX指令集的支持,后者甚至加入了针对AVX-512的支持,不过还需要继续优化。另外,Intel方面自己也开源了一套名为SVT的视频编码器,配合不同后端可以实现不同的编码,对AVX和多核的优化相当好。
深度学习方面,Google著名的开源深度学习框架Tensorflow在1.6版本之后就已经需要一颗支持AVX指令集的CPU了,换言之,它应用了AVX指令集。
另外,AVX-512的大宽度让它很适合用来跑深度学习,所以Intel也针对深度学习设计了一套子指令集——AVX-512 VNNI,用来加速深度学习相关的计算,在测试中,它表现出了相当的实力。
加解密计算场景中对CPU的计算吞吐量有较大的要求,此时AVX指令集就可以发挥作用,常见的软件支持就有OpenSSL这个堪称是互联网基石的加密库,另外像很多程序会使用的libsodium加密库也提供了从AVX到AVX-512的优化,而Linux内核也支持使用AVX和AVX2指令集进行加解密计算,还会配合AES-NI这个专用的指令集。实际上目前还有很多数字货币的计算过程支持使用AVX指令集,不过这个应该是真的没有人会用了……
近两三年的大作基本都开始启用AVX指令集来进行计算了,一般在游戏中CPU负责除了图形以外的杂活,比如说计算各种NPC的运动路径,计算各种动体的轨迹这样的杂活。不过近两年也有厂商想让Intel参与进游戏图形计算,甚至是当下热门的光线追踪运算,比如Intel的光线追踪计算库Embree就可以被整合进游戏中,目前已经有《坦克世界》等游戏使用了它,Embree库高度依赖AVX指令集,也对CPU的游戏性能提出了新的阐述方式:直接参与图形渲染。
总的来说,AVX目前还没有完全展露出它的价值,这也是软件优化缺位导致的。不过随着各路编译器的跟进、处理器迭代使得支持AVX指令集的处理器普及,相信我们的常用软件也会加入AVX优化,比如说在图片处理时调用它。配合上已经展开应用的各种生产力应用,AVX的前景非常广阔。

超能网友大学生 2020-07-07 08:40 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
19#
游客 2020-07-05 12:44
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
18#
超能网友一代宗师 2020-06-30 13:52 | 加入黑名单
支持(5) | 反对(0) | 举报 | 回复
17#
超能网友大学生 2020-06-30 13:26 | 加入黑名单
支持(3) | 反对(0) | 举报 | 回复
16#
游客 2020-06-30 13:25
该评论年代久远,荒废失修,暂不可见。
支持(1) | 反对(2) | 举报 | 回复
15#
我匿名了 2020-06-30 13:10
支持(0) | 反对(0) | 举报 | 回复
14#
超能网友一代宗师 2020-06-30 13:01 | 加入黑名单
支持(0) | 反对(0) | 举报 | 回复
13#
游客 2020-06-30 13:00
12#
超能网友大学生 2020-06-30 12:55 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
11#
超能网友一代宗师 2020-06-30 12:27 | 加入黑名单
支持(0) | 反对(0) | 举报 | 回复
10#
超能网友一代宗师 2020-06-30 12:24 | 加入黑名单
支持(0) | 反对(0) | 举报 | 回复
9#
游客 2020-06-30 11:35
该评论年代久远,荒废失修,暂不可见。
已有2次举报支持(4) | 反对(0) | 举报 | 回复
8#
超能网友教授 2020-06-30 11:22 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有3次举报支持(2) | 反对(1) | 举报 | 回复
7#
超能网友博士 2020-06-30 11:12 | 加入黑名单
已有2次举报支持(2) | 反对(0) | 举报 | 回复
6#
游客 2020-06-30 11:10
已有2次举报支持(4) | 反对(0) | 举报 | 回复
5#
我匿名了 2020-06-30 10:53
已有2次举报支持(2) | 反对(3) | 举报 | 回复
4#
我匿名了 2020-06-30 10:48
该评论年代久远,荒废失修,暂不可见。
已有2次举报支持(5) | 反对(2) | 举报 | 回复
3#
超能网友博士 2020-06-30 10:45 | 加入黑名单
已有1次举报支持(5) | 反对(0) | 举报 | 回复
2#
游客 2020-06-30 10:38
该评论年代久远,荒废失修,暂不可见。
已有3次举报支持(0) | 反对(2) | 举报 | 回复
1#