今年对Intel来说可谓充满挑战,消费级桌面平台虽然升级了LGA 1200平台,但Comet Lake明显就是在Rocket Lake到来之前撑场面用的,移动平台方面动作就大得多,Tiger Lake处理器绝对是Intel今年的重头戏,和它一同推出的还有雅典娜创新计划的第二版规范和关键体验指标的认证——Intel Evo平台,我们之前测试的华硕灵耀X逍遥笔记本用的就是Tiger Lake处理器,同时它也是通过EVO平台认证的产品,此前我们没有对它的处理器进行测试,现在再来看看Tiger Lake的性能表现如何。


Tiger Lake就是上一代Ice Lake的接任者,与上代处理器相比,Tiger Lake采用了更先进的10nm SuperFin制程,CPU内核也从Sunny Cove升级到了Willow Cove,在制程与架构双升级的加持下,单核性能有了明显的提升。核显方面Tiger Lake引入全新的Xe-LP GPU,图形性能是Tiger Lake关注的重点。而且Tiger Lake还增加了对PCI-E 4.0、Thunderbolt 4支持和USB4的支持。
大家都知道,Intel的10nm制程卡了很多年,致使原本规划好的产品多次延期,在去年八月的时候,Intel终于向市场推出了Ice Lake这个首款10nm制程处理器,但刚推出的那段时间可以说出货量仍然受制于制程良率等问题,不是很高。并且Ice Lake的性能表现明显被制程工艺给限制住了,过低的基础频率、过高的发热影响到了它的发挥。
经过一段时间的优化调整,Intel在Tiger Lake上将启用新的10nm SuperFin(以下简称10nm SF)制程,它其实就是之前宣传时候用的10nm+制程,不过为了避免混淆,Intel给它起了个新的名字。

新的10nm SF主要调整了FinFET晶体管的几个物理特性,并改良了制造工艺、引入了SuperMIM和新的阻隔材料等,种种改良使得10nm SF的晶体管能够承受更高的电流,同时有更好的性能。经过调整之后的10nm SF可以让Tiger Lake的主频上到更高的水平。
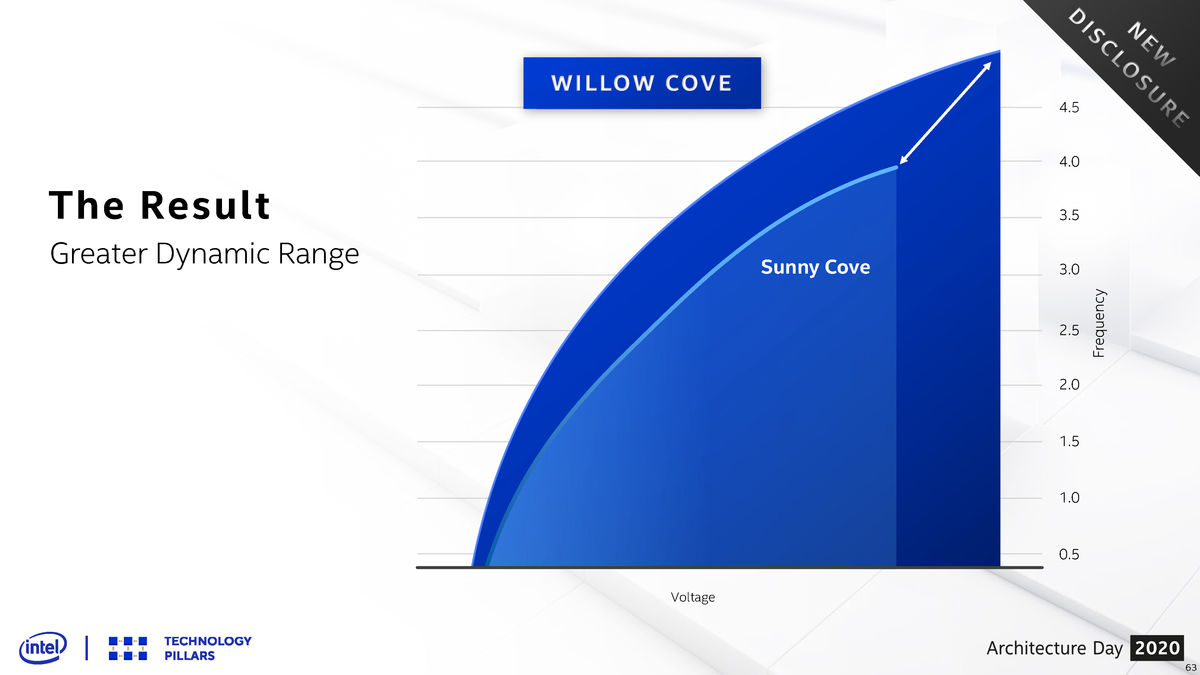
在新工艺的帮助下,Willow Cove内核的电压-频率曲线好看了不少,在同样电压下它能够上到更高的频率,而且它还能够承受更高的电压,最高频率比使用老工艺的Sunny Cove高出不少。
如果直接拿目前泄漏出来的频率信息来对比的话,TDP同为28W的Core i7-1068NG7和Core i7-1165G7,后者的基础频率高了500MHz,最高的睿频可以去到4.7GHz,比前者高出600MHz。另外Intel还在Tiger Lake处理器阵容中规划了更为高端的Core i7-1185G7,其拥有更高的频率。
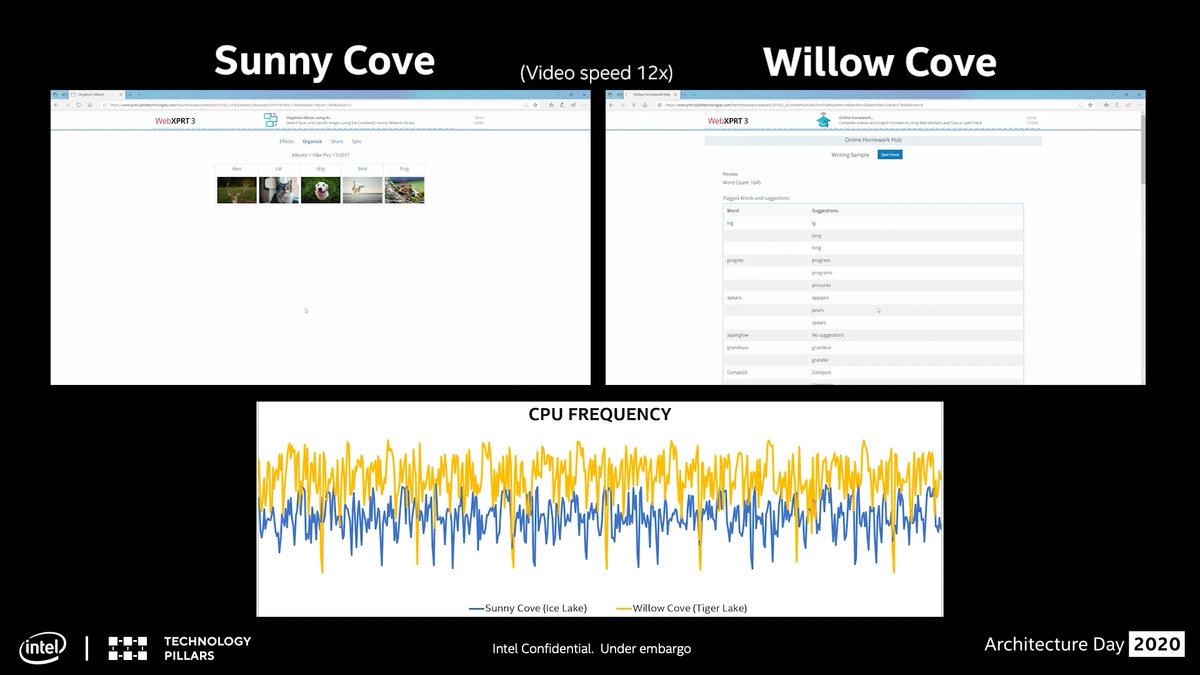
新工艺带来的当然不仅仅是峰值频率的提升,还改善了处理器频率的稳定性,从上面这张图中可以看到,Willow Cove的平均频率明显要比Sunny Cove要高出一个档次,内核掉到最低频率的次数也少了很多。
另外,对于GPU,新工艺也可以说是有巨大的帮助,和内核一样,它在频率范围上有了较大的进步,更具能效比。
在AMD率先在低压端推出8核处理器之后,Intel这边因为各种原因很难在核心数量上进行跟进,那么主频就是用来拉近距离的武器了,在10nm SF的加持下,Tiger Lake的单核性能肯定会有一定的提升,而多线程也能拉近一定的距离,但在多出一倍的核心数面前还是难以匹敌。
除了借助制程进步提升了CPU的频率外,Tiger Lake也继续对内核微架构进行调整升级。在Sunny Cove拨动了Intel处理器上多年未变的IPC指标后,Willow Cove将接过棒,继续拉高自己的单核性能。Willow Cove的内核微架构基于Sunny Cove,是后者的改良版,其中最大的改变点在于它的缓存系统。
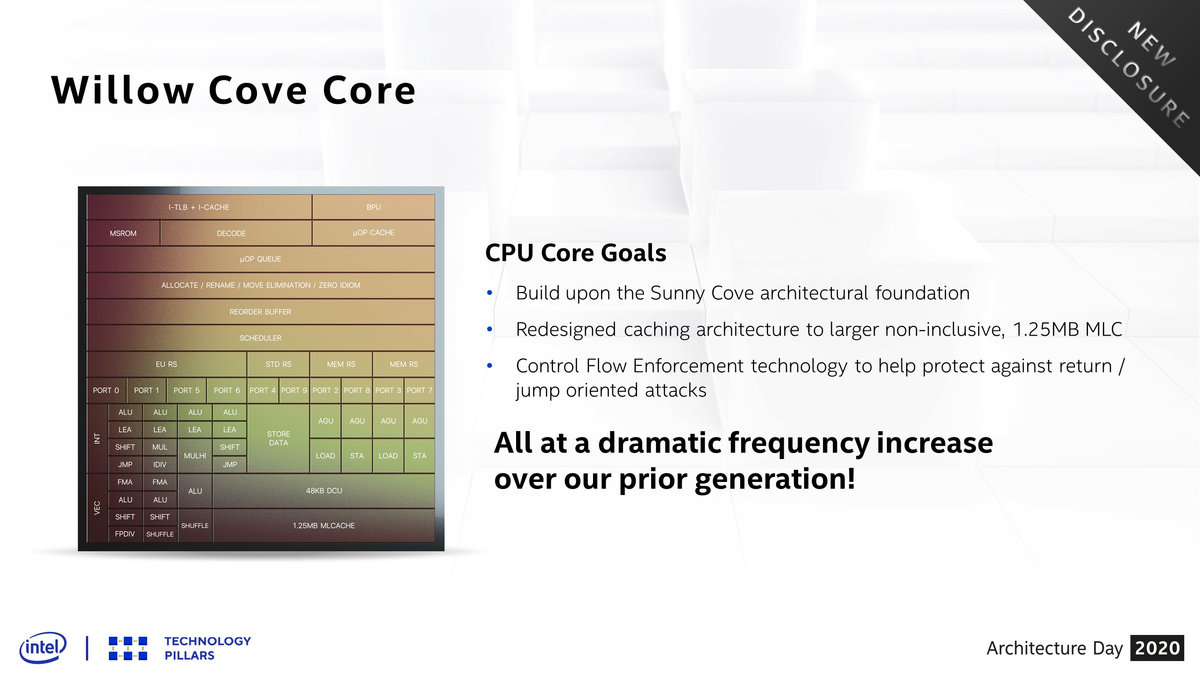
在Willow Cove上,Intel放弃了沿用多年的包含式L2缓存(L2缓存中包含L1缓存的数据),换用了非包含式的结构,同时将它的容量大小从原本的512KB提升到1.25MB,猛增150%。更大的缓存意味着缓存命中率会有提高,2.5倍的大小会让L2缓存的miss机率降低约58%,对单核性能会有很大的帮助。另外非包含式的缓存因为不用做验证了也会带来一定的性能提升。
但是容量越大的缓存其访问延迟会更高,为了平衡掉延迟增加带来的性能损失,Intel将访问带宽从原本的8路扩到了20路,用增多每次访问的数据量去抵消访问延迟增加带来的性能损失。而核心间共享的三级缓存也同样改成了非包含式的,大小则是从每核心2MB增加到每核心3MB,总计12MB,不过访问带宽被砍到了12-way,这意味着在Tiger Lake上,访问三级缓存将会变得更慢,而且访问带宽会变小。
为什么Tiger Lake不集成更多的Willow Cove核心呢?因为大容量的SRAM会占据掉很多核心面积,单个Willow Cove内核的面积应该比Sunny Cove要大不少,加上新的面积贼大的Xe-LP GPU,如果为了放入更多的核心再扩大Die的面积,那么良率会很难看。
其他方面的改动主要有安全特性的更新,最近几年Intel的处理器一直有曝出各种漏洞,最为主要的还是针对分支预测器的攻击,于是Willow Cove在内核层面上引入了新的安全特性,也就是控制流执行(Control-Flow Enforcement)。

CET通过在内存中建立一个影子堆栈来保护原始内存堆栈,同时CET还会实行间接分支跟踪,以防御恶意指向的跳转或调用目标,它有希望在硬件层面上防范掉一系列恶意攻击,不过需要软件支持。
相比起Skylake到Sunny Cove,Willow Cove的变化小了很多,大部分结构直接保留了Sunny Cove的,前端中部和后端都没有什么变化,所以它的IPC提升应该是不大的,其性能提升基本上是来自制程工艺给到的更好的频率表现。

内存控制器方面,Tiger Lake仍然支持DDR4-3200,对LPDDR4X的支持从3733MHz提升到了4266MHz,除了支持这两种现在很常见的DRAM之外,Tiger Lake还预留了对LPDDR5的支持,能够支持LPDDR5-5400。在内存支持规格有提升以外,Tiger Lake的内存控制器还支持全内存加密特性,能够抵御硬件攻击。
从Sandy Bridge开始,Intel在消费级处理器上一直都是用Ringbus环状总线做内部互联的,它的带宽非常高,在核心数量不是很多的情况下能够提供很低的核心间通讯延迟。此次Tiger Lake上,因为核显的增强,其对带宽的需求增加了许多,为了满足它的需求,Intel做了一个双环Ringbus,直接把带宽增加了一倍。
如果说CPU内核微架构的改良算是小菜的话,那么Tiger Lake引入全新的Xe-LP GPU可以说是它身上最大的变化了。是的,图形性能是Tiger Lake关注的重点,开发多年的Xe架构将会在Tiger Lake上首次出演。

Xe-LP架构是Xe架构中面向于移动产品的变种,架构的主要关注点是能效比,也就是要在尽量低的能耗下提供尽量强的性能。本次架构日活动上面,官方带来了Xe-LP架构的具体细节,在这里我们需要对比上一代核显架构来分析它的变化。
Tiger Lake集成的Xe-LP GPU拥有96组EU单元,在规模方面较上代核显大了50%。

类似于另外两家的GPU架构,Intel的GPU架构也有层级之分,最上层的被称之为Slice。每个Slice都有完备的计算和渲染能力,它包含有几何和光栅前端、线程分配单元、执行单元、材质单元和ROP后端。Xe-LP的单个Slice规模比上代扩增了50%,因此,不止是EU,几乎是所有单元的数量都多了50%,不过前端部分没有变化。

在单个Slice之下是Subslice单元,Xe-LP的单个Slice含有6个Subslice单元,它的概念比较类似于NVIDIA的SM和AMD的CU。Xe-LP GPU的单个Subslice单元中含有16个EU。
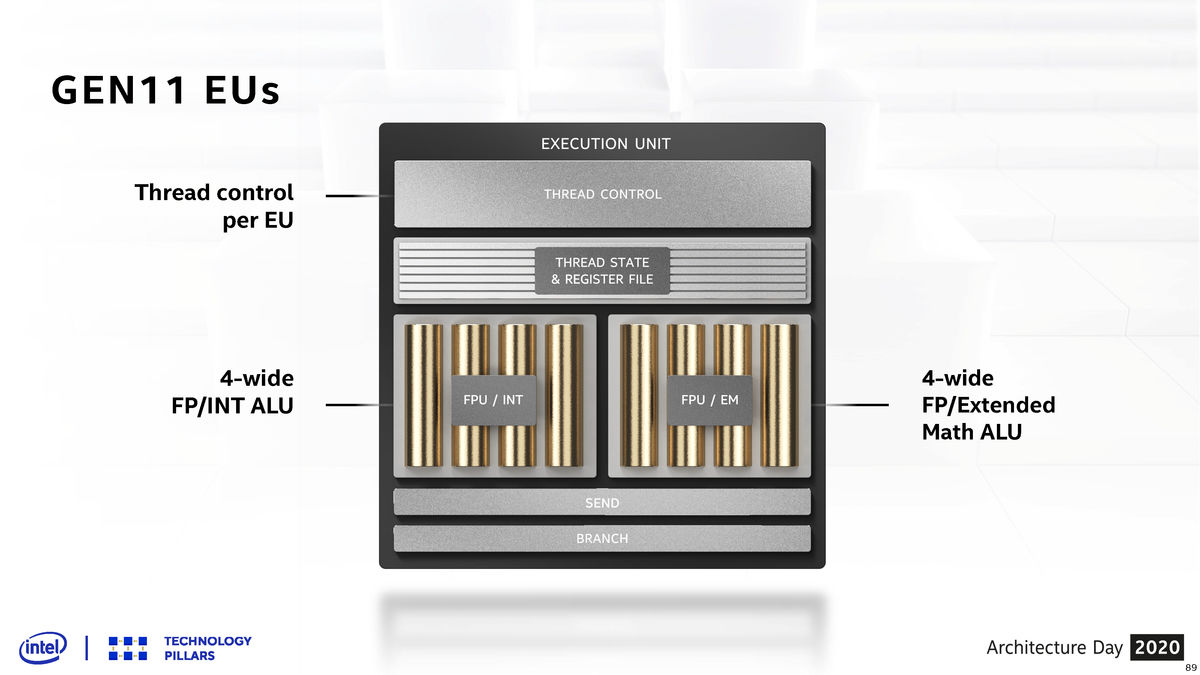
我们继续深入,来看到EU的内部。在上代核显上,一个EU内部有一个线程控制单元,它指挥一组4+4宽度的ALU,其中右边这个ALU还需要负责扩展数学指令的运算。如果遇到相应指令,那么会阻塞掉浮点指令的计算。

那么在Xe-LP上,Intel大刀阔斧的对EU内部进行了调整,首先原本一对一的线程控制单元现在变成一对二了,也就是一个线程控制单元实际要负责两个EU的任务。再往下,到具体的ALU上面,现在每个EU中含有8个用于处理浮点或整数指令的ALU,另外还有两个只针对扩展数学指令的ALU,从原本的4+4结构变成了8+2,而且两种类型的指令可以并行处理了。

看完EU内部发生的变化,再来说说新GPU的缓存系统。

Xe-LP为每个Subslice设计了独立的L1数据缓存和纹理缓存,这是全新的特点。另外GPU有独立的16MB L3缓存,这个容量可以说是非常大了。另外,为了满足核显对内存带宽的高需求,Intel把原本的单环Ringbus改成了双环Ringbus,其带宽增加了一倍。
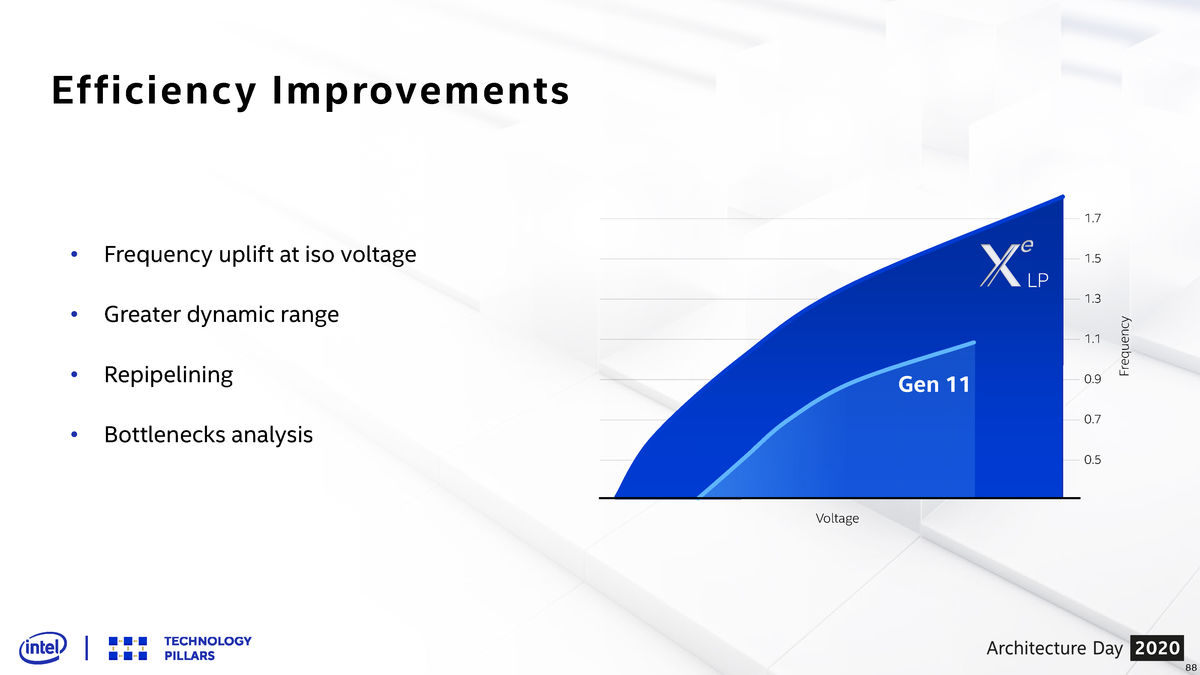
配合10nm SuperFin工艺在频率上的提升,新的核显有着更高的能效表现,如图所示,它能够接受更广的电压范围,还能上到更高的频率,这也是新核显有更强性能的一个原因。在官方的宣传中,新的核显能够提供多一倍的图形性能,不过具体到游戏表现上,还是要看软件优化做的怎么样了。
Xe-LP GPU还带来了加强过的显示引擎和媒体引擎。

显示引擎方面,有四条4K分辨率级别的处理管线,支持两条eDP,外部输出接口则是支持DisplayPort 1.4和HDMI 2.0,当然,具体的输出接口可以是DP和HDMI,也可以是USB-C。其他像是8K输出、HDR10、Dolby Vision、12-bit BT2020色域和自适应同步都有支持,对显示器的刷新率,最高可以支持到360Hz。这里很可惜的是,我们没能见到原生的HDMI 2.1支持,厂商可能会通过转接芯片去做支持。

媒体引擎方面,整个处理管线的编解码性能提升了一倍,色深的支持升级到了12-bit,并且能够支持HDR/Dolby Vision的回放。这里还有一个亮点是对AV1做了硬件解码支持,这是一个面向于未来的特性。
作为一枚SoC,它自然是包含了各种IO控制单元,Tiger Lake在这方面也有较大的提升,主要有PCI-E 4.0支持、Thunderbolt 4支持和USB4支持等几点。

长久以来,Intel的移动低压处理器并不提供直连SoC的PCI-E总线,外围PCI-E设备都是连接到PCH,然后通过OPI总线与SoC进行互连的。但OPI总线那点可怜的带宽放到今天实在是不够用了,所以Intel终于给移动低压处理器做了直连SoC的PCI-E总线,一做就是4.0版本的,这也使得Tiger Lake成为了Intel首颗支持PCI-E 4.0的处理器。官方并没有给出Tiger Lake上具体有几条直连SoC的PCI-E总线,不过从8GB/s这个数据来看,应该是4条。
有直连SoC的PCI-E总线意味着部分对带宽有高要求的外围设备能够发挥出更好的性能水平,比如说独立显卡,比如说PCI-E 4.0的SSD,总之,这4条总线的作用还是很大的。
然后是USB4和Thunderbolt 4的整合,去年Intel在Ice Lake上面首次将Thunderbolt控制器整合到了SoC上,从此Thunderbolt设备就直接连到SoC上,而不是绕PCH。对于一些很吃延迟和带宽的外接设备,直连能够带来可观的性能收益,关于这点我们在之前的显卡扩展坞测试中提过。相比起前代,Thunderbolt 4并没有在速率上有任何的提升,Tiger Lake仍然是会在笔记本的每侧提供一个40 Gbps的Thunderbolt 4接口。Intel还在新的移动超能机型认证中加入了快充的要求,想要通过认证的笔记本就必须要有一个支持快充技术的Thunderbolt 4接口。而USB4的支持则是让Tiger Lake有更好的兼容性,虽然到目前为止市场上还没有出现任何USB4设备,但早做准备总归是不会错的。
移动平台是一个对功耗非常敏感的平台,所以每代移动平台在功耗管理上都会做出改进,以适应新的应用场景。

Tiger Lake的功耗管理单元更新了动态电压和频率调节算法,另外现在SoC上的IO单元也能够独立地进行睡眠。总的来说,Tiger Lake将会更为省电,具体到产品表现上,续航将有一定的延长。
在已经进入到AI时代的大背景下,移动SoC厂商们纷纷在自己的产品上加入了NPU等单元来加速AI推理等运算,Intel在Ice Lake上首次置入了一个名为GNA的加速单元,它能够针对部分AI应用进行加速,Tiger Lake上,这个单元升级到了2.0版本。

在笔记本上面,GNA单元主要被用于处理语音识别,官方给出的数据表示,GNA 2.0单元在1mW的功耗下能够提供1 GigaOP的性能,由于没有Ice Lake的对比数据,也不清楚2.0的升级幅度有多大。

另外一直存在于Intel SoC上的一个默默无闻的单元就是图像处理单元(IPU),Tiger Lake集成了第六代IPU,依旧支持6个传感器,但是在规格上能够支持4K90的视频和4200万像素图片的处理。不过呢,这是未来Tiger Lake-H上面的IPU规格,目前的Tiger Lake-U系列只能够支持4K30的视频和2700万像素的照片。

测试用的是华硕灵耀X逍遥笔记本,作为首批上市的EVO平台笔记本,它通过了严酷的EVO平台认证标准,要求笔记本必须有:1、真实应用集严格测试;2、长电池续航 (1080p屏幕下大于9小时);3、即时唤醒(小于1秒);4、快速充电(1080p屏下,充30分钟能用4小时);5、采用英特尔Wi-Fi 6以及雷电4高速连接。
华硕灵耀X逍遥搭载了英特尔第11代Tiger Lake-U架构的Core i7-1165G7处理器,4核8线程,基础频率1.2GHz,最高可睿频到4.7GHz,12MB L3缓存,Xe核显拥有96个EU,最大频率可以达到1.3GHz,而默认的PL1只有15W,但可以通过软件拉到35W,PL2也能提到51W。配备16GB双通道LPDDR4X内存,频率4266MHz,硬盘则是一个1TB的WD SN730 NVMe SSD。

用来做对比的是以前测试的戴尔XPS 13 9300,它用的是Core i7-1065G7,是第十代的Ice Lake处理器,同样是4核8线程,基础频率1.3GHz,最高睿频3.9GHz,8MB L3缓存,配备64EU的Intel Iris Plus 940核显,16GB双通道LPDDR4-3733MHz,但需要注意的是,我们测试这款笔记本的时候PL1与PL2分别拉到46W和61W,功耗上限比华硕灵耀X逍遥高得多 ,散热也更好,所以性能对比仅供参考。
虽然说功耗限制有明显差不,但Core i7-1165G7的整数与浮点计算能力还是明显比Core i7-1065G7更高,用Sandra 2020测出来整体提升有18%左右,但负载触碰到功耗限制的话,结果就不这样了。
从上面的测试能看得出,采用Tiger Lake架构的Core i7-1165G7在单线程性能上比上一代的Ice Lake的Core i7-1065G7有很明显的提升,多线程测试由于功率和散热的限制,看起来Core i7-1065G7比Core i7-1165G7还要强,但实际上如果采用同样散热和功率设计的话是不会出现这样的结果的。
核显性能这里我们加入了另外两个参照物,一个是Comet Lake-U上的UHD620,另一个则是NVIDIA的入门级独显MX250,用配备Xe架构核显的Core i7-1165G7性能比上代Gen 11核显性能暴增了65%以上,甚至比MX250还要更强,随着核显性能的暴增,笔记本入门级显卡性能是时候再翻一翻了。
我们所用的AIDA64版本对Tiger Lake支持还是有点问题,内存频率识别有问题,L2缓存的延迟测试也有问题,Tiger Lake对LDPPR4X内存的支持从3733MHz提升到4266MHz,所以带宽提升了将近20%,延迟也从89ns降低到了60ns,缓存方面,随着单核频率的增加,L1与L2缓存的带宽也等比提升,L3缓存带宽提升则和CPU频率提升没太大关系,主要还是环形总线从单环变成了双环,延迟降低也最明显的。
Tiger Lake相比于上一代的Ice Lake来说,制程工艺上的收益是非常明显的,10nm SuperFin工艺让Tiger Lake的频率从Ice Lake的最高3.9GHz提升到了4.8GHz,有900MHz的频率差距啊。内核上的改良则相对较少,Willow Cove其实就是Sunny Cove的小改,主要是缓存方面的改动,内核就加了些安全补丁,从测试结果上来看Core i7-1165G7的单线程性能比Core i7-1065G7强得多,多线程由于两台笔记本功耗设置不一样没法得出准确结论。
核显也是Tiger Lake的一大改良点,Xe-LP的性能确实比入门级核显更强,比上一代的Gen 11核显有了很大的提升,让15W的低功耗处理器也有不错的3D图形性能,不过呢,核显始终是核显,它还得和CPU内核分TDP和内存带宽,限制还是很多的,笔记本上的入门级显卡还是会继续存在的,不然Intel也不会弄个Xe-LP的独显版本出来。
I/O方面的升级也非常重要,第11代酷睿处理器支持PCI-E 4.0,那么SSD也是时候升级换代了,随着各大厂商都推出新一代PCI-E 4.0 SSD,笔记本上的SSD也将会逐渐过渡到PCI-E 4.0时代,此外整合了Thunderbolt 4和USB4控制器,让笔记本厂商能用更低的成本去提供这些接口,这些新接口能大幅提升用户体验。
从现在Tiger Lake-U上的表现,大家可以期待一下未来不知道什么时候才会出来的Tiger Lake-H,毕竟Tiger Lake-U可以说成Ice Lake-U的小幅改进,但Tiger Lake-H和Comet Lake-H比起来可是翻天覆地的改动。

超能网友大学生 2020-12-25 15:48 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(4) | 反对(0) | 举报 | 回复
15#
超能网友一代宗师 2020-12-25 08:56 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有8次举报支持(12) | 反对(5) | 举报 | 回复
14#
超能网友博士 2020-12-24 23:26 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(7) | 反对(0) | 举报 | 回复
13#
超能网友教授 2020-12-24 23:03 | 加入黑名单
已有1次举报支持(5) | 反对(1) | 举报 | 回复
12#
我匿名了 2020-12-24 21:56
11#
超能网友终极杀人王 2020-12-24 19:22 | 加入黑名单
10#
超能网友编辑 2020-12-24 18:03 | 加入黑名单
已有1次举报支持(2) | 反对(0) | 举报 | 回复
9#
超能网友终极杀人王 2020-12-24 17:50 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有3次举报支持(1) | 反对(0) | 举报 | 回复
8#
超能网友终极杀人王 2020-12-24 17:27 | 加入黑名单
已有6次举报支持(4) | 反对(5) | 举报 | 回复
7#
超能网友编辑 2020-12-24 17:21 | 加入黑名单
已有1次举报支持(2) | 反对(0) | 举报 | 回复
6#
超能网友编辑 2020-12-24 17:20 | 加入黑名单
已有1次举报支持(1) | 反对(0) | 举报 | 回复
5#
超能网友终极杀人王 2020-12-24 17:13 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有6次举报支持(3) | 反对(4) | 举报 | 回复
4#
超能网友教授 2020-12-24 16:47 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有5次举报支持(5) | 反对(2) | 举报 | 回复
3#
超能网友一代宗师 2020-12-24 16:31 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(1) | 反对(0) | 举报 | 回复
2#
我匿名了 2020-12-24 16:16
该评论年代久远,荒废失修,暂不可见。
已有2次举报支持(1) | 反对(0) | 举报 | 回复
1#
提示:本页有 2 个评论因未通过审核而被隐藏