NVIDIA在CES 2021上除了公布了新一代甜点卡GeForce RTX 3060之外,重点产品其实是GeForce RTX 30系列笔记本电脑GPU。其实在桌面市场上我们早已经见识过了NVIDIA新一代GeForce RTX 30系GPU,那相比GeForce RTX 20系翻倍的性能提升幅度,这得益于全新NVIDIA Ampere架构带来的跨跃式进步,而现在GeForce RTX 30系列笔记本电脑也会是一次性能全面大提速。

NVIDIA首批发布的GeForce RTX 30系列笔记本电脑GPU包括GeForce RTX 3080、RTX 3070与RTX 3060,在CES 2021的发布会上,NVIDIA表示GeForce RTX 3080与RTX 3070是定位1440p分辨率游戏的,前者可在开启光线追踪技术的情况下,提供100+的FPS帧数表现,而后者则可提供90FPS最高画质表现,目前搭载这两款笔记本电脑GPU的游戏本已经开卖,而GeForce RTX 3060笔记本电脑GPU则是面向1080p分辨率游戏的,可在最高画质达到平均90帧的画面表现。
目前NVIDIA GeForce RTX 3080/3070 Laptop GPU是游戏本上1440p分辨率游戏的最佳选择,可提供最高画质的同时带来流畅的帧数,并且现在NVIDIA Ampere架构的新特性也应用笔记本上,包括NVIDIA Reflex、NVIDIA Broadcast、NVIDIA Studio等,还有新增的第三代Max-Q技术以及Resizable BAR技术。
GeForce RTX 3080、RTX 3070笔记本电脑GPU使用的是GA104核心,而GeForce RTX 3060笔记本电脑GPU则使用GA106,后者的详细信息还没有公布,而前者则是桌面版GeForce RTX 3070、RTX 3060 Ti所使用的GPU,核心面积392.5mm2,晶体管数量174亿,采用三星为NVIDIA定制的8nm工艺生产。
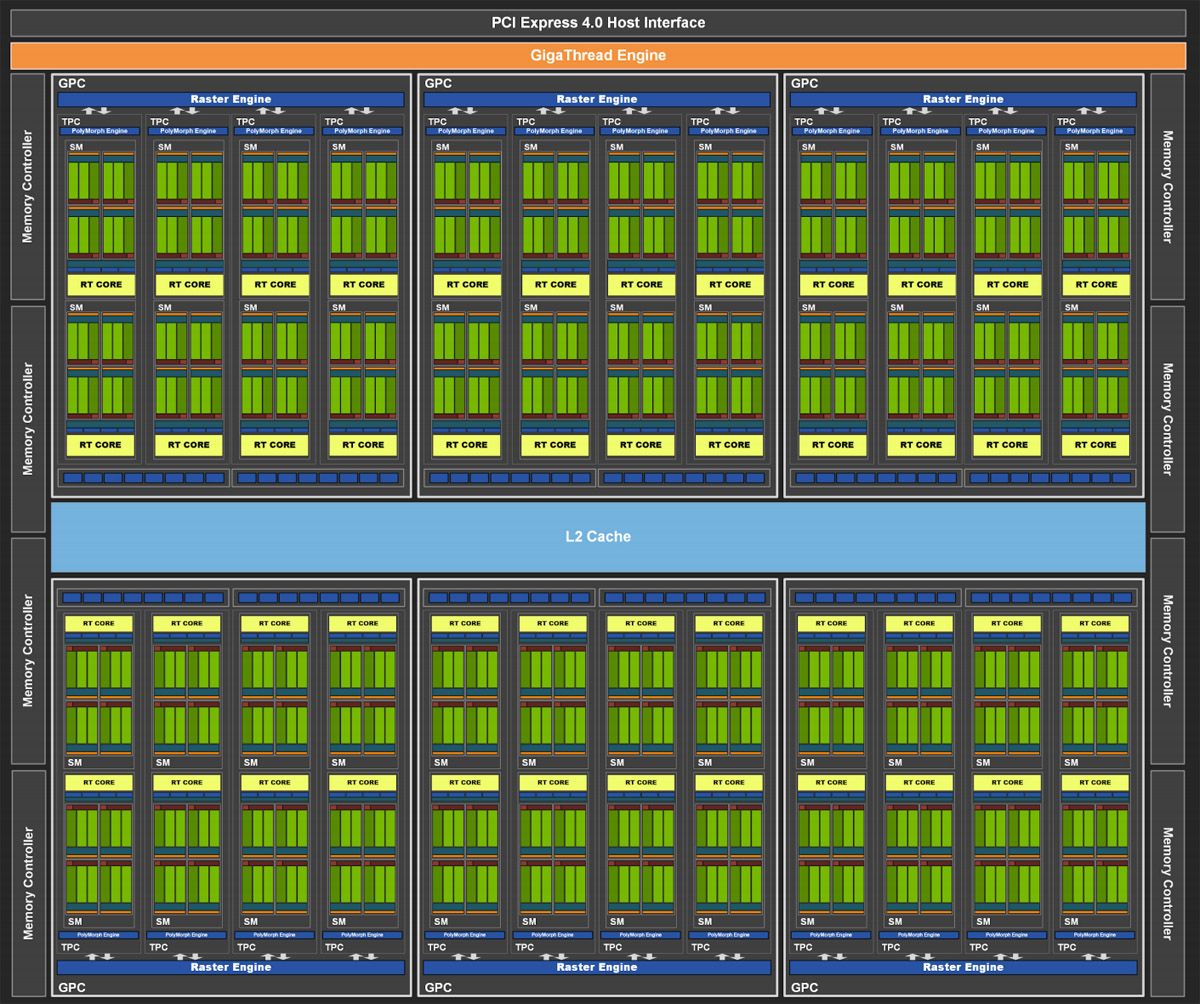
GeForce RTX 3080笔记本电脑GPU用的是完整版的GA104核心,拥有6组GPC,每组有4组TPC,一共24组TPC,每组TPC包含2组SM(Streaming Multiprocess),所以总共拥有48个SM(Streaming Multiprocess),每组有128个CUDA,一共有6144个CUDA,8组32位的显存控制器组成256bit的显存位宽。
GeForce RTX 3080笔记本电脑GPU只启用了40个SM(Streaming Multiprocess),一共有5120个CUDA,但依然保留了256bit的显存位宽。
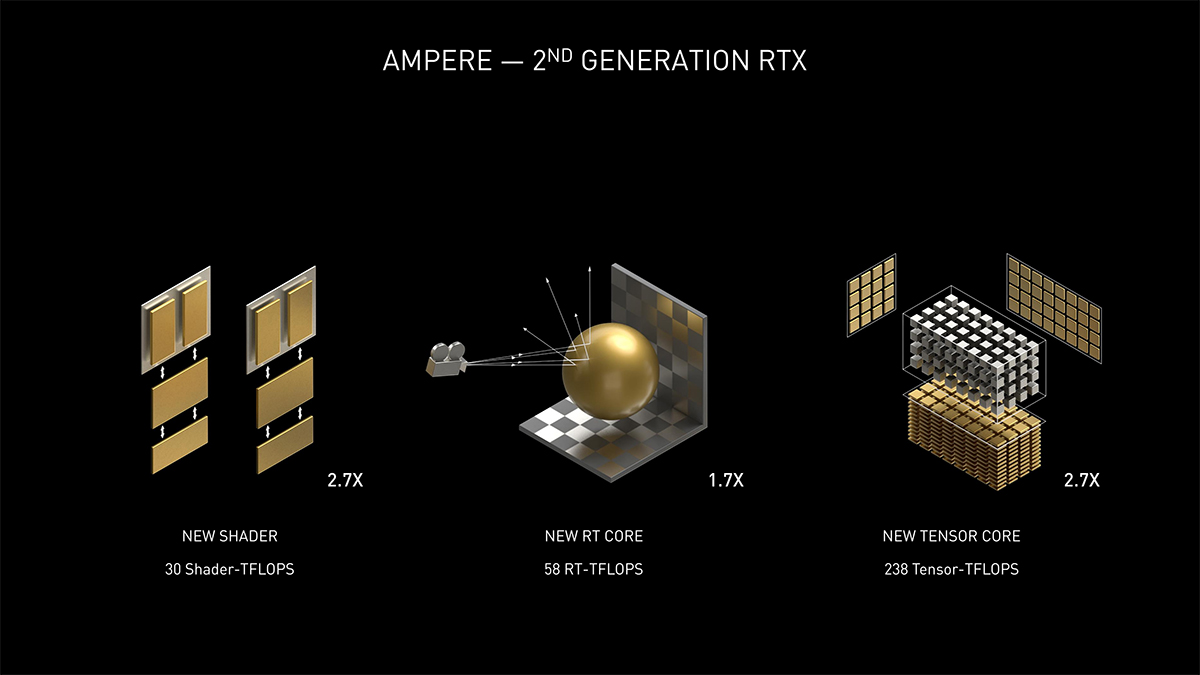
2018年8月份,NVIDIA在推出RTX 20系列显卡的时候着重介绍了他们的RTX概念,将实时光线追踪和AI计算引入到了GPU中,其SM(Streaming Multiprocess)可以说是发生了翻天覆地的变化。NVIDIA在NVIDIA Ampere架构上则是着重提升了整个SM(Streaming Multiprocess)的性能表现,虽然在结构上没有做出太大的修改,但性能已经不可同日而语。主要提升有三点,针对传统图形计算的FP32单元加倍、引入第二代RT Core和第三代Tensor Core。

NVIDIA Ampere架构SM(Streaming Multiprocess)的性能两倍于Turing架构
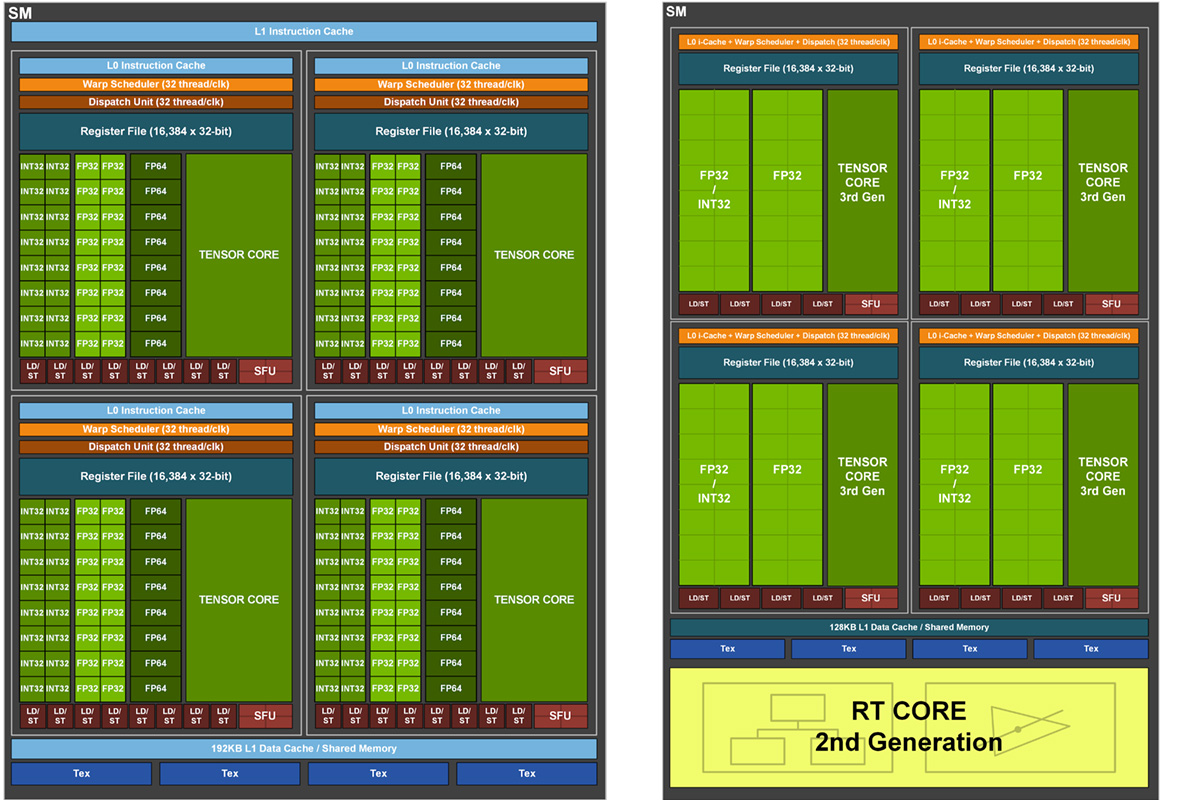
GA100(左)对比GA102(右)
在NVIDIA Turing架构上面,NVIDIA引入了分数据类型计算的理念,将整数型(INT32)和单精度浮点型(FP32)两种不同的数据类型交给两种不同的ALU进行计算,大大提高了SM(Streaming Multiprocess)的并行计算效率。不过现代游戏应用中最为常见的还是FP32,也就是单精度浮点类型的计算,INT32 ALU的使用率是要比FP32 ALU的低的。为了提升计算效率,NVIDIA引入了可同时支持INT32和FP32两种数据类型的新ALU,取代了原本只支持INT32计算的ALU。也就是说,现在有两条不同的数据路径(Datapath),一条能够处理整数或单精度浮点,另一条只能处理单精度浮点计算。

原本一个SM(Streaming Multiprocess)又被划分成四个更小的区块,每个区块有自己的调度器和寄存器,能够调度16个INT32 ALU和16个FP32 ALU,整个SM(Streaming Multiprocess)同时可以处理64个INT32计算指令和64个FP32计算指令。到了NVIDIA Ampere架构上则是变成128个FP32计算指令或64个INT 32计算指令和64个FP32计算指令。在遇到以FP32为主的图形计算时,其计算吞吐量最高可以提高到原本的两倍。
另外NVIDIA也更新了CUDA核心的计数方式,现在以一个FP32 ALU为一个CUDA核心,所以在NVIDIA Ampere架构上,每个SM(Streaming Multiprocess)拥有的CUDA核心数倍增到了128个。
为了配合规模有一定扩张的计算单元,NVIDIA对每个SM(Streaming Multiprocess)的缓存系统也进行了一定的改良。NVIDIA Ampere架构SM(Streaming Multiprocess)的共享缓存/L1数据缓存容量从96KB增长到了128KB,同时其带宽变为原来的两倍,实现容量带宽双增长。
在NVIDIA Turing架构上,NVIDIA首次引入了能够针对实时光线追踪运算进行加速的RT Core。在执行实时光线追踪相关的计算时,现代的基于SIMD的CUDA核心在进行光线和物体表现碰撞点等计算时表现出来的效率太低,反而是基于MIMD架构的特定用途计算模块更为高效。NVIDIA的RT Core就是这样一种专门为实时光线追踪计算进行加速处理的专用硬件单元。
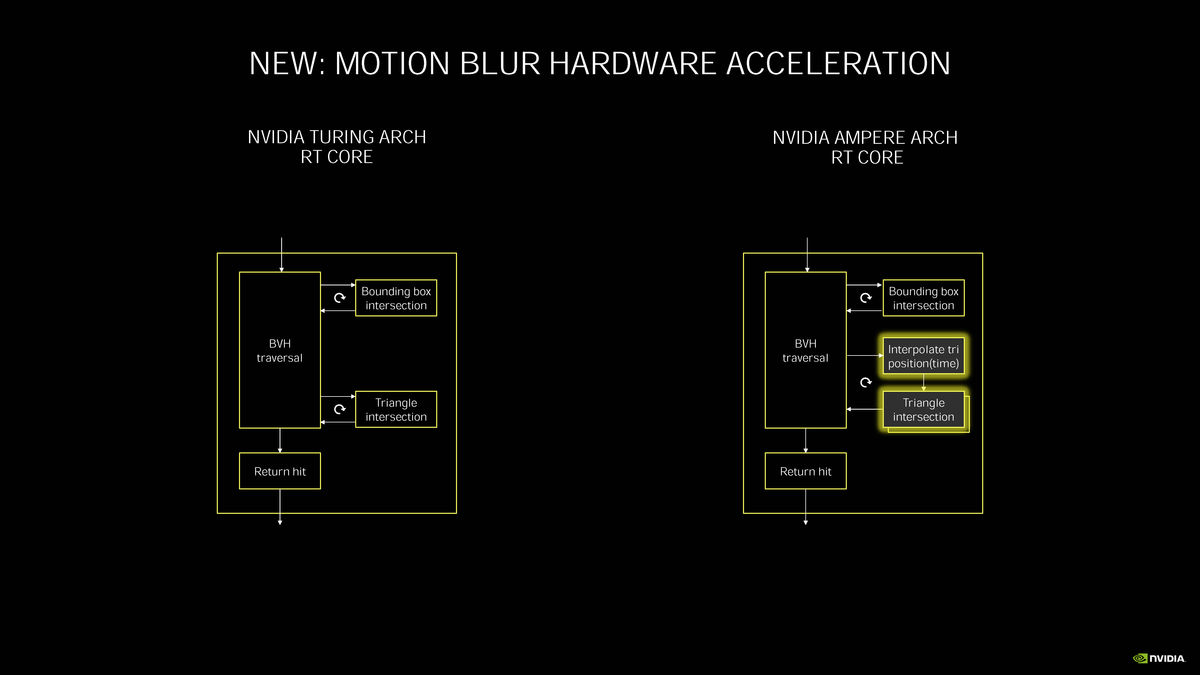
NVIDIA Ampere架构GPU上的RT Core主要是增加了对动态模糊的加速运算支持。在非光追情况下的动态模糊往往只是对画面套用后处理滤镜,其效果并不真实。在实时光追情况下,动态模糊则是通过实时计算物体与光线的交互情况所产生的,其运算非常复杂,就算是Turing上面的RT Core也难以承载。到了NVIDIA Ampere架构,其第二代RT Core中加入了NVIDIA设计的插值算法,在保证动态模糊精确性的同时提高了该情况下的实时光线追踪效率,官方称最高可以实现8倍于前代的速度。另外,在基础的BVH计算上面,新一代RT Core也能够快上2倍。
从NVIDIA Volta架构开始,NVIDIA就在SM(Streaming Multiprocess)中引入为AI计算优化的Tensor Core,这些张量计算单元能够提高显卡在机器学习计算上的效率。在NVIDIA Ampere架构上,Tensor Core已经进化到了第三代,它能够提供比第二代Tensor Core高出4倍的效能。不过游戏卡上面的Tensor Core进行了一定的精简,其FP16 FMA计算的吞吐量只有GA100核心中的Tensor Core的一半。
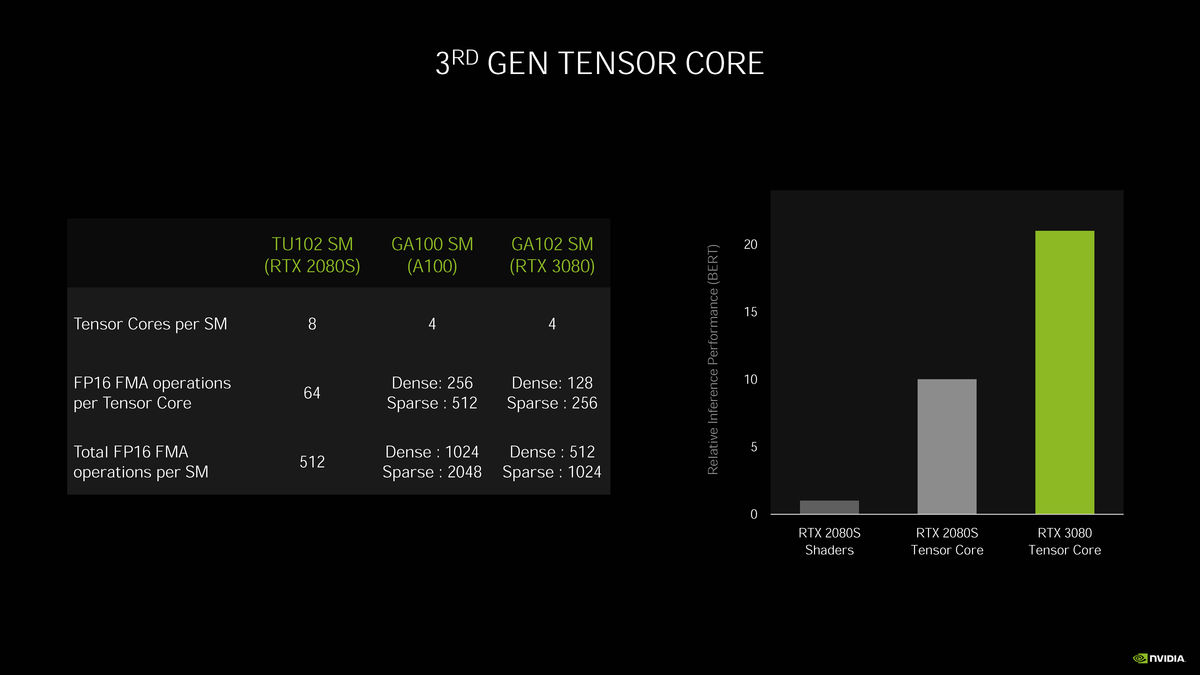
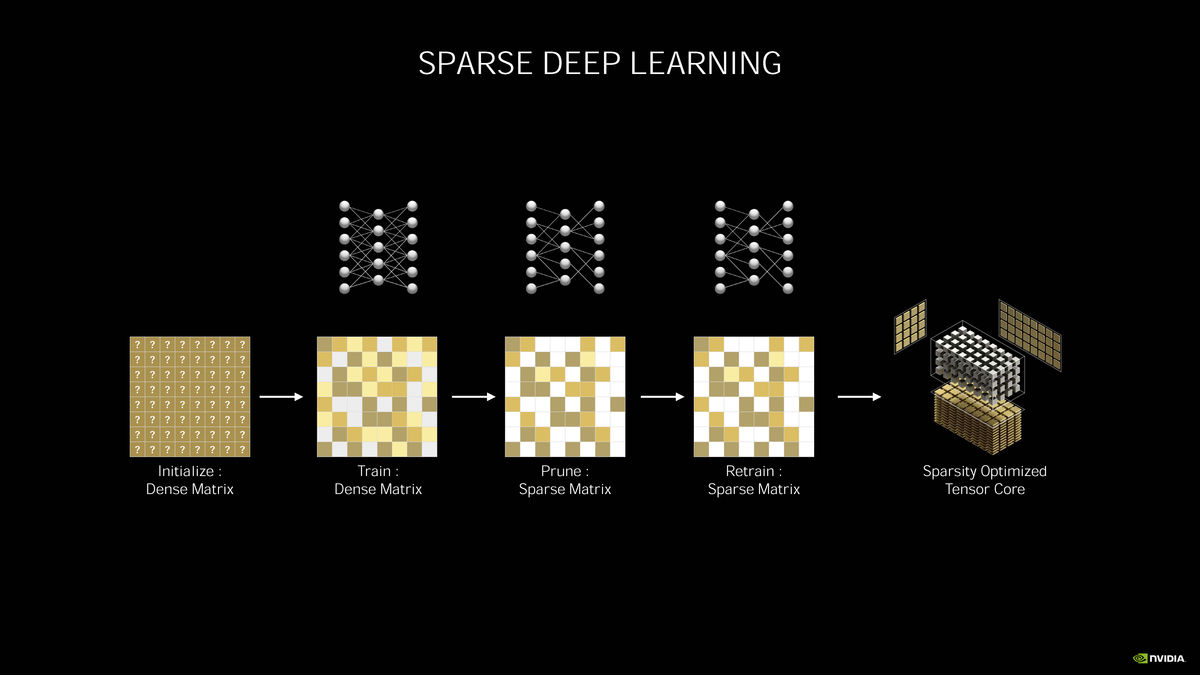
第三代Tensor Core除了在效能方面有提升之外,还对稀疏矩阵运算提供了支持,详细的介绍可以看我们之前对计算卡方向的NVIDIA Ampere架构的解析:《NVIDIA新一代Ampere架构简单解读:一次有改良有革命的架构升级》。总的来说,即便是面向游戏的NVIDIA Ampere架构将每SM(Streaming Multiprocess)的Tensor Core数量从8个减到了4个,它的整体效能仍然是有很大提升。
新的Tensor Core带来的更强劲的AI算力将会为DLSS助力,在今年早些时候,NVIDIA开始全面推广DLSS 2.0技术,相比起初代DLSS,DLSS 2.0不管是在画面质量还是在渲染效率上都有很大的提升,已经不再是所谓的鸡肋功能,能显著提高游戏性能,保障1440p分辨率下游戏本的流畅度,并且开启DLSS后对GPU来说渲染压力低了,可以有效降低游戏时GPU功耗,进而延长电池的续航时间。

首先,DLSS 2.0在效率和处理速度上有很大的提升,NVIDIA宣称其速度可以达到原版的两倍,换到实际游戏中就是同样的设置下可以提高更多的帧数。
然后是更好的图像超采样质量,DLSS 2.0扩展了超采样的倍数,可以支持4x的分辨率拉伸,也就是说 ,在1080p的渲染分辨率下通过DLSS 2.0即可拉伸到4K分辨率,大大节约了GPU资源,可以提供更高的帧数。
最重要的一点是,DLSS 2.0不再需要针对单个游戏进行模型学习推理了,现在所有游戏都会使用一个模型,这大大降低了游戏开发商使用DLSS技术的门槛,未来整合DLSS技术将会是一件非常简单的事情。
将不同类型的计算交给不同的单元去处理是从NVIDIA Volta架构就开始采纳的一种理念,当时引入的Tensor Core分流了很多AI相关的运算,而在其后引入的RT Core又将实时光线追踪相关的计算给分流了。那么它们可以并行执行吗?可以,但并不是全部运算都能够并行执行。
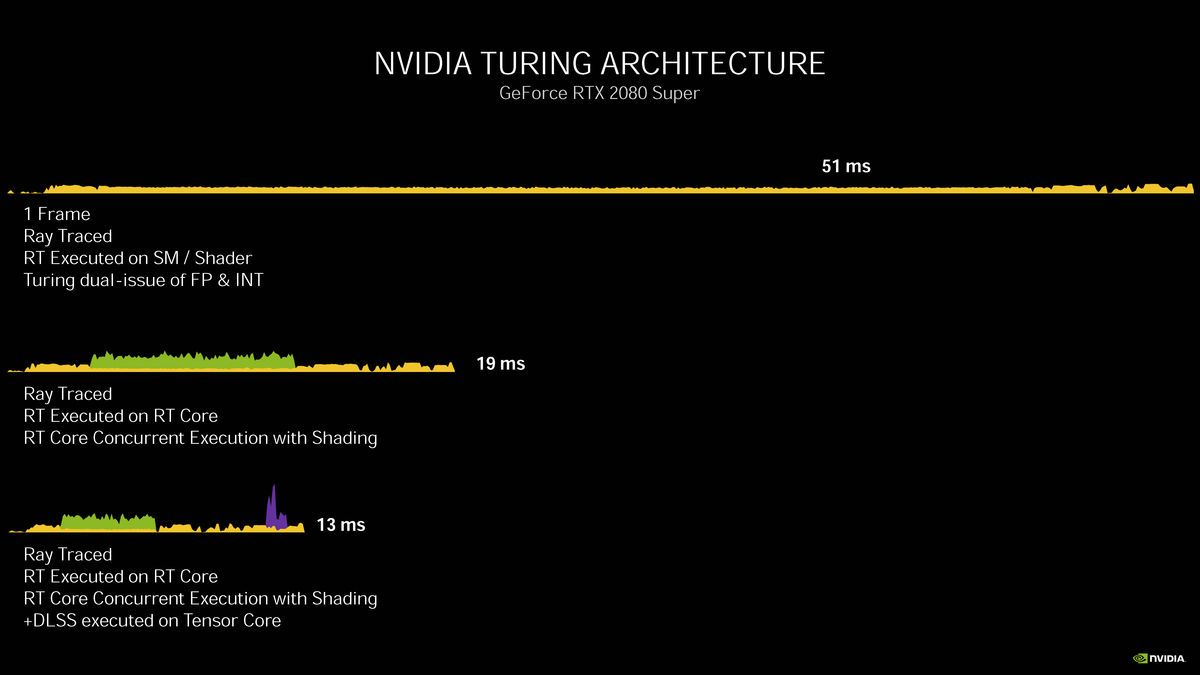
如上图所示,Turing GPU在开启实时光追和DLSS时,其RT Core和Tensor Core并不是并行工作的,Tensor Core被调用的时间点已经接近整个渲染流程的末尾,它没有和RT Core同时运行。

在NVIDIA Ampere架构上,NVIDIA提升了GPU内部各种单元之间的并行性,现在传统计算单元、RT Core和Tensor Core这三大单元可以同时工作,在原本基础上继续缩短帧渲染时间。
Max-Q是一种系统层级的技术,它为轻薄游戏笔记本电脑提供出色的性能。从芯片、软件、PCB 设计、到功耗分配和散热系统,笔记本电脑的各个部分都针对功率和性能进行了特别优化。第三代Max-Q技术通过AI和全新的系统优化选项,引入了WhisperMode 2.0和Dynamic Boost 2.0,让高性能游戏笔记本电脑的表现远超以往。
在这次的GeForce RTX 30系列笔记本电脑GPU上,NVIDIA还为游戏本引入Dynamic Boost 2.0技术,因为在绝大多数主流的游戏本内部,都采用了GPU与CPU共享散热系统和功耗的方案,这就存在GPU和CPU可能会资源分配不合理的情况,比如在游戏里面,有些是偏重GPU的,也有可能CPU会在某些场景中调用得更多,而一般游戏本都是固定的功耗分配,导致无论哪边需求更高,也不会分配到更多资源。

而NVIDIA这个Dynamic Boost 2.0技术,就会根据不同游戏不同场景的性能需求,结合AI技术分析游戏运行情况,自动调节GPU和CPU的功耗分配、GPU与GPU显存的功耗,以发挥出各自最大的运行效率,官方宣称最高可以带来16%的性能提升。
WhisperMode 2.0可将游戏笔记本电脑的噪音控制提升至新的高度。WhisperMode经过彻底的重新设计,并从系统层级定制化的构建到笔记本电脑中,但并不是所有搭载RTX 30系列GPU的笔记本都会配备此功能,决定权在厂商手上。在选择自己想要的噪音级别后,WhisperMode 2.0 的AI驱动算法便可通过管理 CPU、GPU、系统温度和风扇转速,在为您提供良好的噪音表现的同时,依然保持卓越的性能。

过去,游戏笔记本电脑的静音模式主要通过降低风扇速度来实现的,这会限制系统性能或导致温度升高。WhisperMode 2.0是一种更为复杂的系统级控制器,可在用户选择的噪音级别内实现最大化性能。利用AI驱动的算法可动态管理CPU功率,GPU功率,系统温度和系统风扇速度,以在选定的噪音级别上提供最佳体验。
除了噪音级别外,用户还可调节最小帧率目标来确保流畅的游戏体验,为用户提供了超高效的模式,使笔记本电脑在游戏和创作时更加安静。
为了利用上PCI-E接口的高速连通特性,NVIDIA还借着这次RTX 30系列GPU的更新,公布了Resizable BAR技术,主要是让CPU可以直接通过PCI-E访问GPU的显存,让两者之间的数据交换更为直接,而不用再通过系统内存,特别是如今游戏文件越来越多、越大,在传统的访问模式中容易出现数据排队等待的情况,Resizable BAR就可以让CPU与GPU在游戏中做到更高效的处理。

但NVIDIA这项技术其实不仅要靠GPU硬件来实现的,还需要笔记本厂商在主板设计,以及游戏开发商这边的优化配合,预计在今年内,新款游戏本和游戏都陆续会有通过补丁升级支持Resizable BAR技术。
伴随GeForce RTX 30系桌面GPU一同发布的,有一个对于电竞游戏,或者更仔细地说对于电竞选手来说很重要的新东西,那就是NVIDIA Reflex,现在该技术也被带到笔记本上。那么这个NVIDIA Reflex到底是什么东西呢?其实它是分为两部分的,一部分是硬件,一部分是软件。
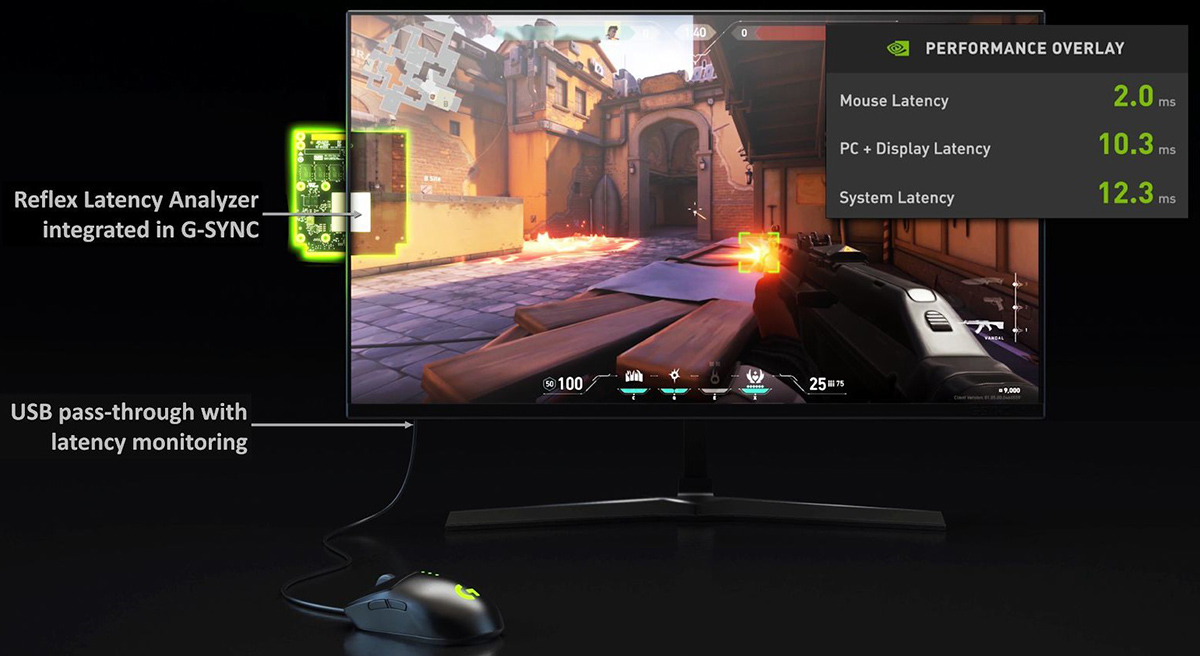
硬件部分是一个与我们这次使用的LDAT很相似的东西,叫Reflex Latency Analyzer,它其实可以视作为LDAT的一个进阶版本,是直接预安装在显示器里的,可以用来测量玩家从点击鼠标直到画面出现变化之间的时间差,也就是整套系统的所有延迟。

而软件部分则是NVIDIA Reflex SDK。这个NVIDIA Reflex SDK的作用是降低以及测量渲染延迟的,开发者可以直接整合到游戏内。而在开启其低延迟模式后,可以让CPU与显卡同步,大幅度减少渲染序列,从而降低渲染延迟。
NVIDIA Broadcast是为直播主们推出的,这用到RTX GPU的AI能力来对直播主的背景消除或替换,还有摄像头重构图,甚至帮助麦克风进行背景噪音消除。
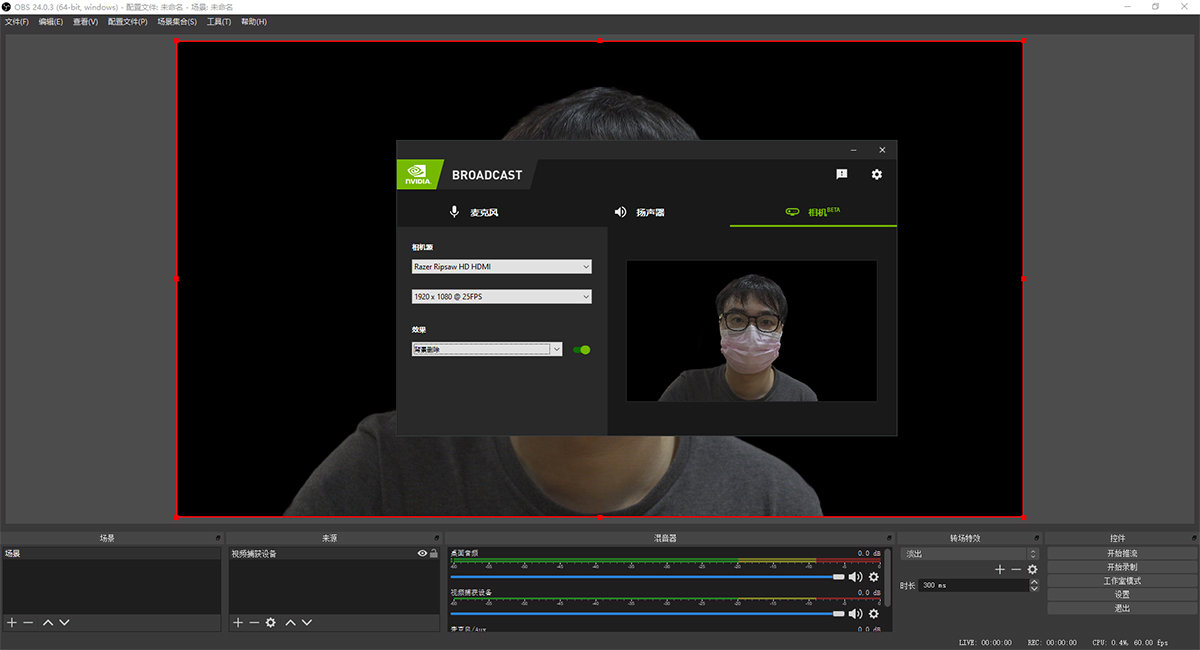
在安装了NVIDIA Broadcast软件后,它会在摄像头、耳麦与直播软件之间建立一个中间者的角色,让外置设备可以利用到RTX GPU的AI能力来做一些AI增强效果,耳机和麦克风现在支持了降噪功能,AI会分析出哪些是主要音频,哪些是背景杂音进行降噪,给直播主和观众呈现清晰、有用的声音。
而摄像头现在有了自动重构图以及背景处理能力,从摄像头采集到画面,可以设置经过Broadcast进行处理,再传到OBS这些直播软件中,这可以让直播主的背景变得更为生动灵活,同时也可以降低直播场景的搭建成本。
RTX Studio这一概念是NVIDIA在2019年提出的,因为NVIDIA觉得GeForce RTX系列GPU其实不仅限于用在玩游戏上,随着近年内容创作市场对硬件需求的增加,NVIDIA希望RTX系列显卡也能让内容创作者们受益,而RTX Studio笔记本则为满足创作需求,面向个人创作者、工作室用户。NVIDIA Ampere架构在通用计算的SM(Streaming Multiprocess)、专为光线追踪运算的RT core,以及用于AI运算的Tensor core,这三个主要部分都作了大幅度的改进,这三大特性对于如今主流的创意应用,也能进一步提速。
因为在RTX Studio支持的创意应用中,目前已经有大量主流软件利用上了RTX系列GPU的这三大特性,比如视频剪辑软件Premiere Pro支持基于CUDA的水银硬件加速,3D动画制作软件Blender可利用RT core来提高渲染速度,还有DaVinci Reslove、Photoshop、Lightroom在Tensor core帮助下,实现更快更准确的AI功能。
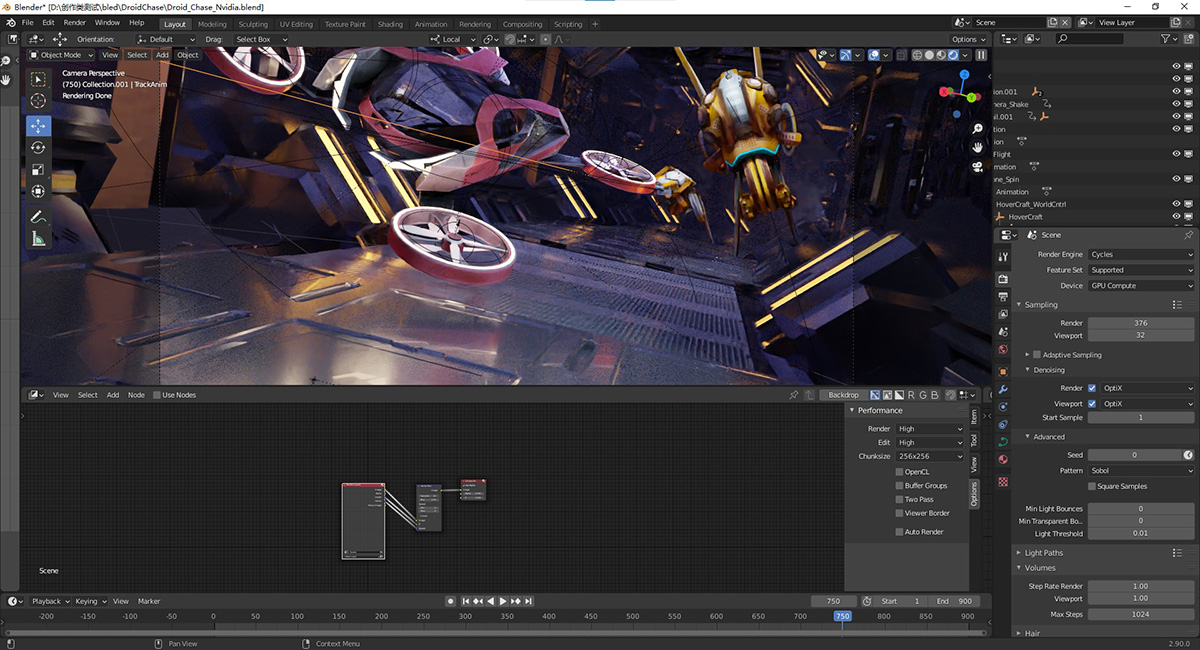
所以RTX 30系GPU这三个大提速,相应地也会帮助那些有利用到这三个特性的创意应用,获得更快速度处理速度,而且不仅如此,一些应用还获得新的功能特性。比如Blender支持了第二代RT core的动态模糊加速,在渲染带有高速运动场景的3D动画中,更好应付当中的动态模糊效果,还有就是基于AI的超采样技术DLSS,现在也可以应用到创意工作中了,室内设计和渲染软件D5渲染器便是首个支持DLSS技术的3D渲染器,大幅提高了图像在实时预览时的帧率。

最后RTX 30系GPU还升级了内置的NVDEC到第五代,支持最高8K分辨率HDR视频的AV1硬解码,这对于有8K HDR视频回放需要的视频后期工作者也会有很大帮助,加上本来的第七代NVENC硬件编码器,最高缩短了五倍的视频导出耗时,以及在直播串流中帮助降低硬件性能消耗。
GeForce RTX 30系列笔记本电脑GPU强劲的性能,让游戏本在开启最高画质加光追的情况下保持较高的帧率。与此同时带来的第三代Max-Q技术里的Dynamic Boost 2.0可自动调节GPU和CPU的功耗分配,以发挥出各自最大的运行效率,WhisperMode 2.0可在用户选择的噪音级别内实现最大化性能。Resizable BAR可让CPU与GPU在游戏中做到更高效的处理。拥有更强大AI性能的RTX 30系列笔记本电脑GPU无论在游戏上还是内容创作上都能给用户体验带来质的改变。


超能网友博士 2021-02-03 10:40 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(1) | 反对(0) | 举报 | 回复
8#
超能网友终极杀人王 2021-02-02 03:22 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(4) | 反对(0) | 举报 | 回复
7#
我匿名了 2021-02-02 03:05
已有1次举报支持(3) | 反对(1) | 举报 | 回复
6#
超能网友一代宗师 2021-02-01 20:00 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(0) | 反对(0) | 举报 | 回复
5#
超能网友终极杀人王 2021-02-01 19:15 | 加入黑名单
4#
超能网友终极杀人王 2021-02-01 18:28 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(1) | 反对(0) | 举报 | 回复
3#
超能网友教授 2021-02-01 16:07 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(6) | 反对(1) | 举报 | 回复
2#
超能网友研究生 2021-02-01 15:02 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有3次举报支持(5) | 反对(0) | 举报 | 回复
1#
提示:本页有 1 个评论因未通过审核而被隐藏