AMD去年推出的Zen 2架构在IPC上基本上就追平甚至略微超过了Intel的酷睿桌面处理器,两者的游戏性能差距其实已经差很少了,多线程性能其实AMD早就是碾压态势,今年Intel推出了第十代酷睿桌面处理器Comet Lake进行反击,但大家看到Comet Lake之后的反应估计和我一样:就这?简单来说Comet Lake就是上一代Coffee Lake处理器再加了两个核心,然后把功耗限制继续往上加,并改良散热硬是拔高频率后的产物,但CPU内核还是五年前的Skylake,简单来说IPC五年没提升过。在Intel原地踏步这几年,AMD就在奋起直追,官方表示全新的Zen 3比起上一代又有了19%的IPC提升,游戏性能更是有了很大的改善,感觉要把对手最后的优势也夺走。

Zen 3这一代处理器的命名直接跳过了锐龙4000系列,新的处理器叫作锐龙5000系列,估计是要让名字和明年初发布的新一代移动处理器同步,不然新的移动处理器又要“领先”桌面处理器一代了。
这次AMD首批推出的第五代锐龙处理器只有四款,但囊括了6核12线程、8核16线程、12核24线程、16核32线程这些中高端重点型号,价格方面国内售价相对上代是有些微升幅,幅度不算很大,目前第五代锐龙处理器型号还不算齐全,后续AMD应该会继续扩充产品线。
16核32线程的锐龙9 5950X,基础频率3.4GHz,加速频率能到4.9GHz,64MB L3缓存,105W TDP,售价6049元;
12核24线程的锐龙9 5900X,基础频率3.7GHz,加速频率4.8GHz,64MB L3缓存,105W TDP,售价4099元;
8核16线程的锐龙7 5800X,基础频率3.8GHz,加速频率4.7GHz,32MB L3缓存,105W TDP,售价3199元;
6核12线程的锐龙5 5600X,基础频率3.7GHz,加速频率4.6GHz,32MB L3缓存,65W TDP,售价2129元。

2017年AMD推出了初代Zen架构,对比之前AMD的挖掘机架构可以说是革命性的架构变更,IPC提升幅度高达52%,放弃物理多核模块化设计,回归传统的SMT同步多线程架构,首次引入CCX最小CPU计算单元这概念,每个CCX里面有4个核心,并且配备8MB L3缓存,每个Die上最多两个CCX,并引入Precision Boost与XFR技术。
2018年推出的Zen+可以说是Zen架构的小改,改善了缓存与内存延迟,工艺从14nm升级到12nm,所以最大频率能从4GHz提升到4.35GHz,Precision Boost与XFR也升级到第二代,允许更多线程同时提升到更高的频率,不同线程的负载可以把频率提升到不同水平,不像第一代那样一刀切只能提升两个线程。
2019年推出的Zen 2架构改进就非常之大了,改用台积电7nm工艺,最高频率能达到4.7GHz,依然是4核CCX,但CPU的结构大改,采用MCM多芯片封装,内部被分为了CCD以及IOD两个部分,每块PCB上最多可安装一个IOD和两个CCD,这样的设计让单个CPU的核心数量从8核翻倍到16核,但由于内存控制器安放在IOD内,所以内存延迟明显增加,为了弥补,每个CCX内的L3缓存翻倍到了16MB,内核方面,浮点单元位宽从2x128bit提升到2x256bit,大幅提升执行AVX-256指令的效率,所有的改进加起来让IPC提升了15%,此外Zen 2架构也是首款支持PCI-E 4.0的消费级处理器。
2020年,AMD带来了全新的Zen 3架构,它采用更为成熟的7nm工艺,CCX改成8核心的,单个CCD内原来两个独立的16MB L3缓存也同一成一块32MB的L3缓存,与Zen 2相比IPC提升高达19%。
到底是那些东西让Zen 3有如此之大的IPC提升呢,下面让我们慢慢道来。
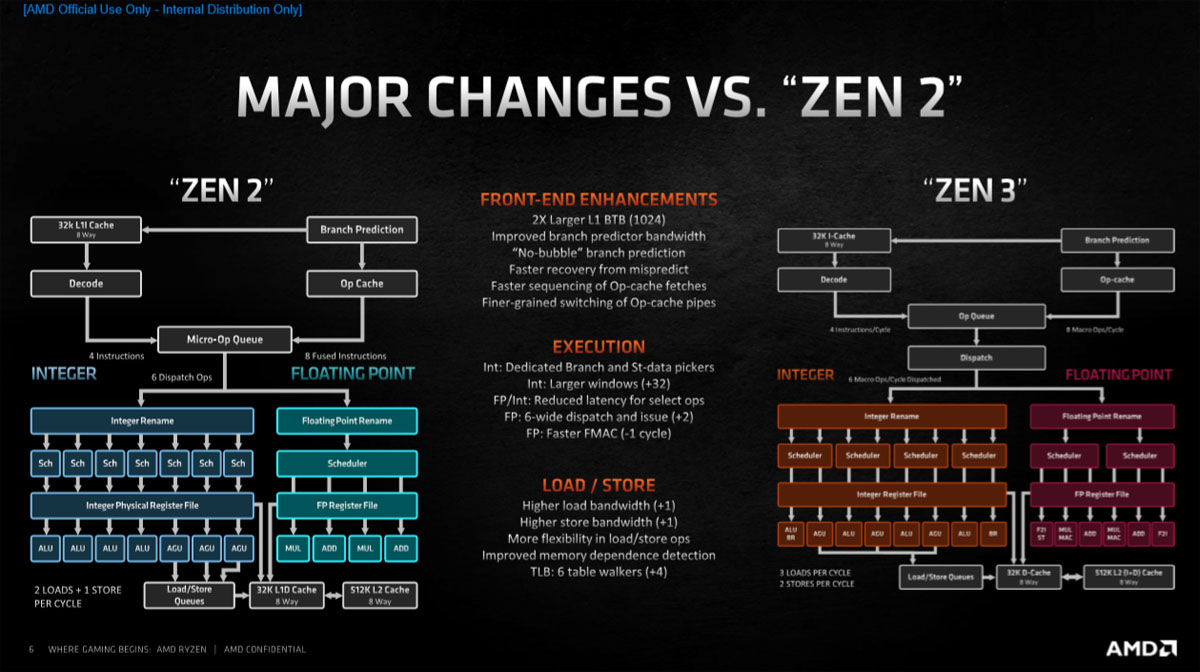
Zen 3与Zen 2架构的对比如上图所示,主要改进地方包括:前端功能增强,能更快地获取代码,尤其是对于分支代码和大尺寸代码;执行引擎减少延迟并扩大结构以提取更高的指令级并行度(ILP);加载/存储有更大的结构和更好的预取,以支持增强的执行引擎带宽。
最大的变化是单个CCX的核心数量从4个增加到8个,现在每个CCD内都只有1个CCX,L3缓存也从两组16MB的统合成单个32MB,减少对主内存访问的依赖性,减少核心到核心的延迟,减少核心到缓存的延迟。这对于PC游戏尤其有用,因为PC游戏往往具有频繁使用L3缓存的特性,现在这些游戏现在能直接访问32MB的L3缓存,而不是16MB。

而19%的IPC提升,是缓存预取、执行引擎、分支预测器、微操作缓存、前端、加载/存储等多个地方改良叠加起来的结果。
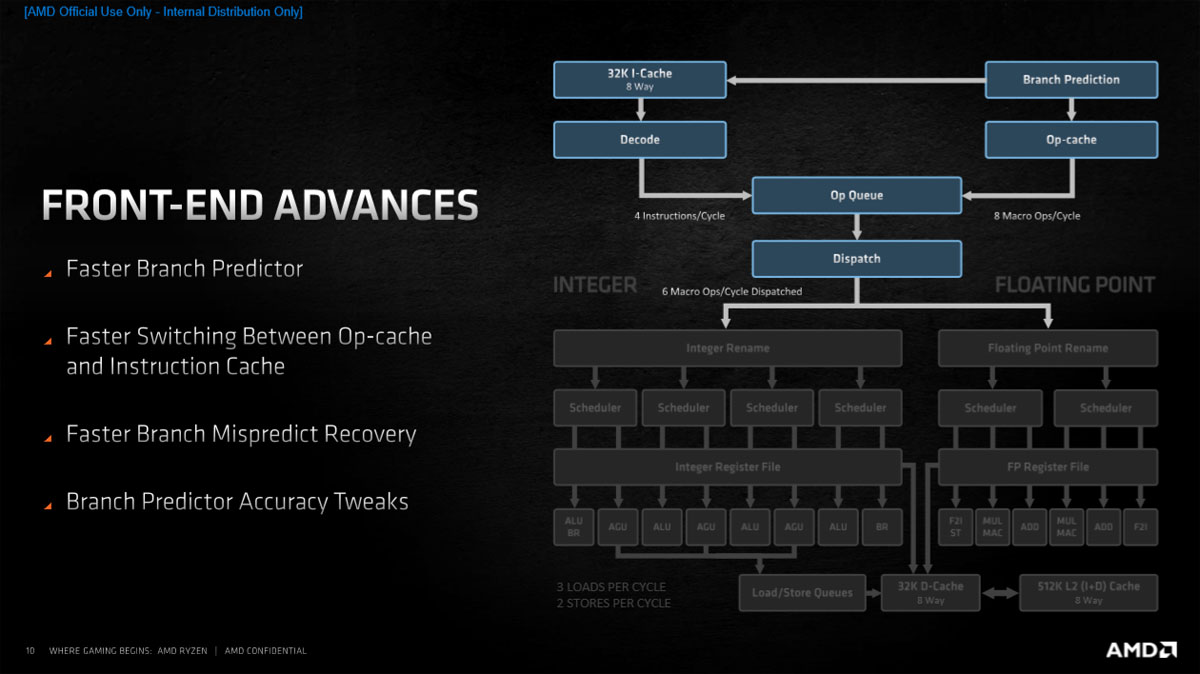
Zen 2架构的前端采用了更快的TAGE分支预测器,每个时钟周期能获得更多的预测,可在操作缓存和指令缓存之间更快地切换,并且能够更快的从错误预测中恢复,分支预测器准确性也进行了调整。
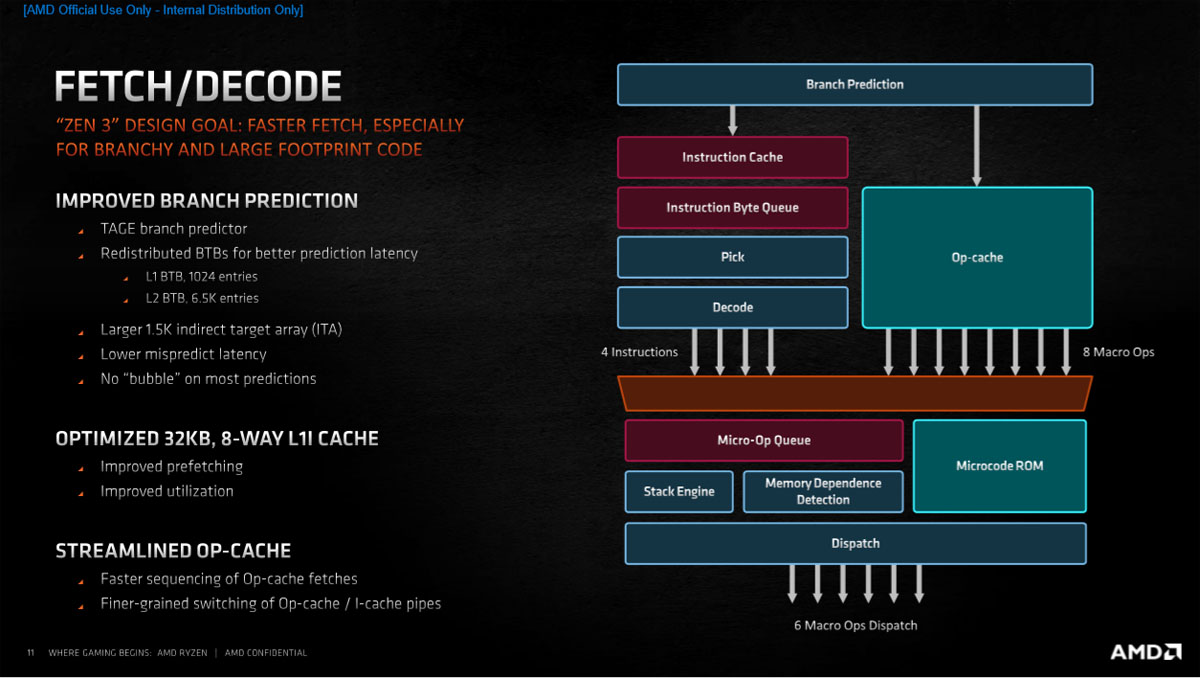
取指令与指令解码系统方面,分支目标缓冲器也有所变化,重新分配各级BTB以获得更好的预测延迟,L1 BTB数量从512条目翻倍到1024条目,L2 BTB数量从7000条目减少到6500条目,ITA也从1000增加到1500,缩短了流水线管道,所以发生预测变量错误时能够更快的恢复,“无气泡”预测功能可更快地预测并更好地处理分支代码。
L1指令缓存依然是32KB 8-Way,但对预取和利用率都进行了改良优化,操作缓存则进行了简化,效率会比Zen 2更高。
执行引擎在整数与浮点方面都进行了改进
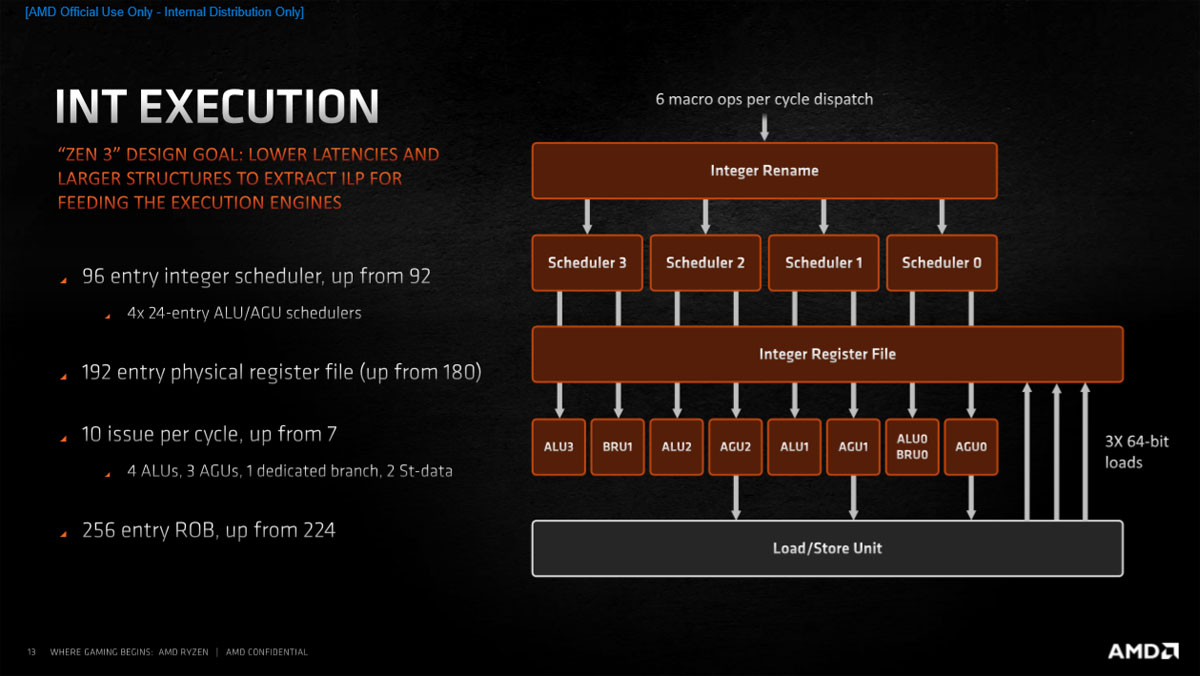
整数单元方面,Zen 3的整数调度器从Zen 2架构的92个条目增加到96个条目,现在有四个24条目的ALU/AGU调度器。物理寄存器文件从180增长到192,从而提供了更大的操作窗口。重排序缓存从224条目增加到256条目。每个内核依然拥有四个整数ALU单元和三个AGU地址生成单元,增加了一个专用分支单元和两个st数据选择器,现在每周期可并行处理10个事件。

Zen 3内核与Zen 2内核的ALU执行单元是相同的,但Zen 3的调度器允许不同工作负载之间均衡共享使用ALU和AGU,这种共享调度制度可提供更大的吞吐量。
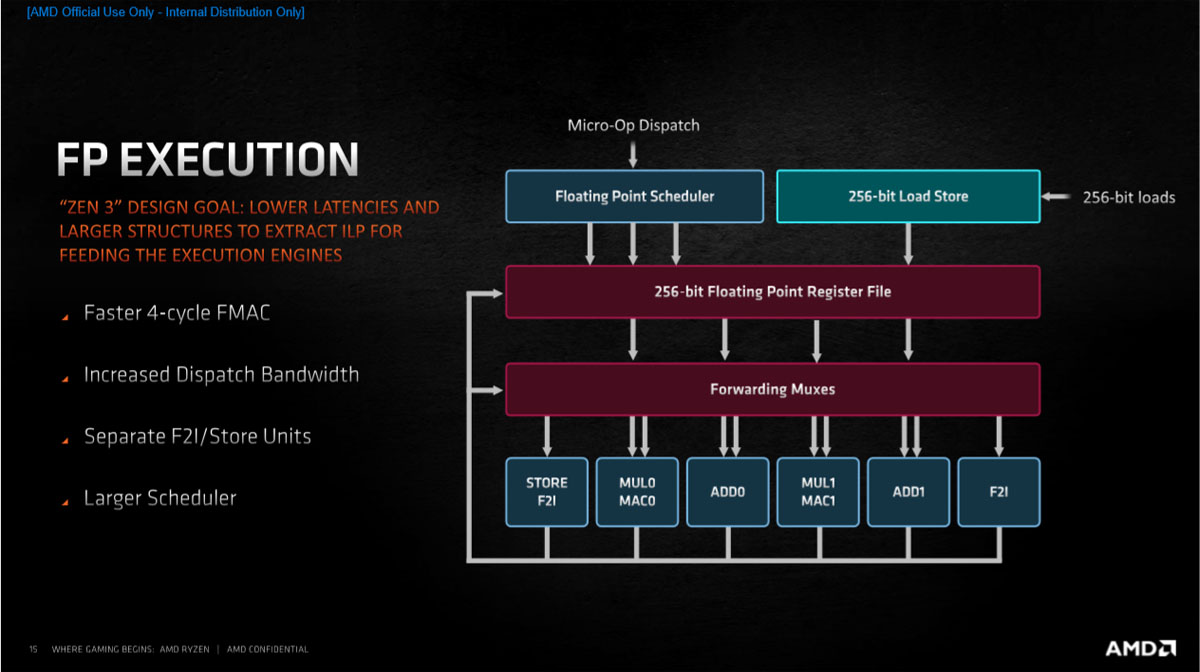
浮点执行单元从4个增加到6个,增加了独立的F2I/存储单元,用于存储和把浮点寄存器文件搬到整数单元,现在MUL和ADD不用在兼顾这些操作了,能够专注自己的工作了,每周期的运算能力更强了,FMAC周期从5缩短到4,使用了更强的调度器,减少了选择浮点和整数操作的延迟。
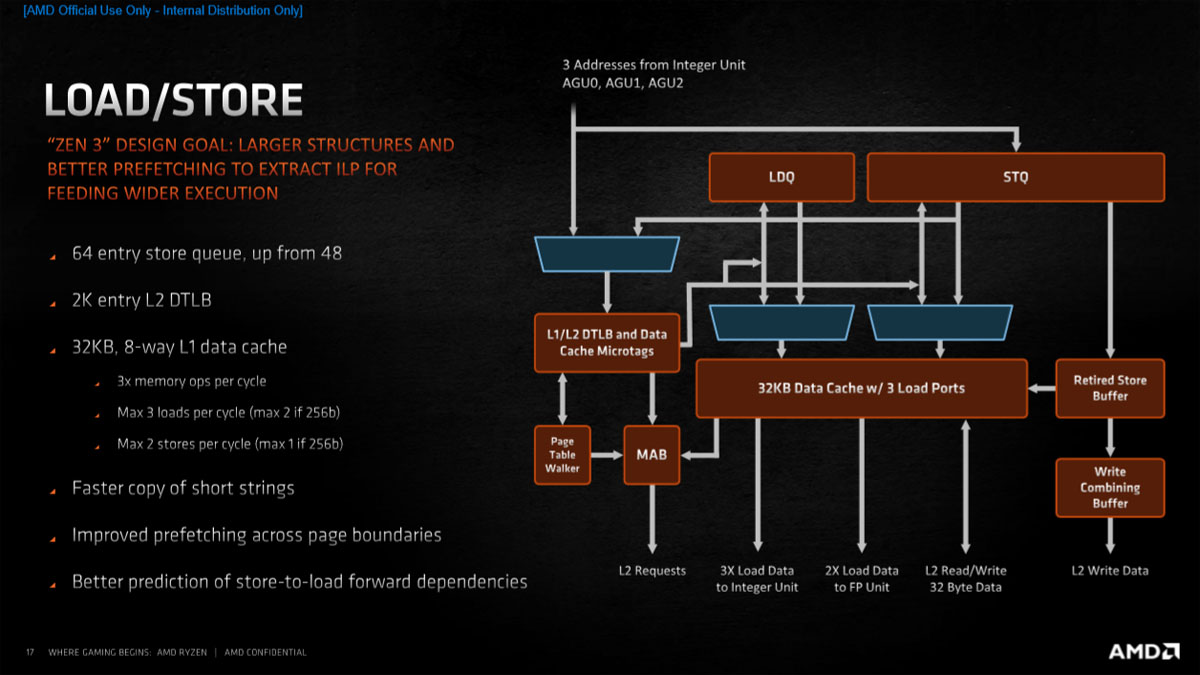
Zen 3内核的存储队列从48个增加到64个,L2 DTLB的数量依然是2K,L1数据缓存依然是32KB 8-Way,但与Zen 2架构的相比,每时钟周期的读取和存储次数都加了一,现在每时钟周期能进行三次读取操作和两次存储操作,但如果是浮点数据的话每周期操作数会减一,读取/存储操作更具灵活性 。
Zen 3架构的CCX进行了改动,现在每个CCX的L3缓存翻了一倍,所以预取算法进行了改动,能更高效的利用更大的L3缓存。使用了新技术缩短了存储-读取这样的转发操作的延迟。整个读取与存储系统有更高的带宽 ,可以满足更大更快的执行资源的需求。

与内核的改动相比,CCX的改动才是最大的,Zen与Zen 2架构每个CCD内都有2个CCX,而每个CCX内包含4个核心,并且有各自独立的8MB或16MB L3缓存,到了Zen 3架构AMD修改了CCX的设计,每个CCX内有8个核心,L3缓存现在也是全部核心共享的32MB,这样能够有效降低CPU核心之间的通信延迟。Zen 2架构即使同一芯片内的CCX之间通信也是要走IOD上的SDF的,延迟非常大,Zen 3架构这一的改动大幅降低了同一芯片内核心通信的延迟,并且能够有效降低内存延迟,随着缓存与内存效能的提升,Zen 3架构能获得更好的游戏性能。
此外由于单个CCX的核心数量从4个增加到8个,CCX的内部总线也一同变了,AMD放弃了一直沿用的XBAR总线,改用了环形总线,毕竟4核互联只需要6条XBAR就足够了,但8核的话需要28条,复杂度大幅增加,改用环形总线确实是更好的选择。


Zen 3的CCD依然是使用台积电7nm工艺生产的,芯片面积是80.7mm2,晶体管数量是41.5亿,而Zen 2的CCD面积是74mm2,内部有39亿个晶体管。IOD依然是那个没换,用GF的12nm工艺,芯片面积125mm2,内部有20.9亿个晶体管。
封装方面这个其实和Zen 2是一样的,一个CPU内包含一或两个CCD合一个IOD,相互之间采用Infinity Fabric总线连接,上行带宽32B每周期,下行带宽16B每周期,所以同样会出现Zen 2那样的单CCD处理器内存写入速度只有双CCD的一半的这种情况。
由于IOD没换,所以内存控制器也是那样有内存频率和IF总线存在1:1或1:2分频的现象,但锐龙5000系列的fclk能跑到2000MHz,所以内存能够跑到DDR4-4000并采用1:1分频,但目前BIOS还有些问题,只有体质好的处理器能跑到2000MHz的fclk,等以后更新到AGESA 1.1.8.0之后就大部分都能达到了。
AMD没有像前三代那样一同发布新的主板芯片组,确实新的处理器依然采用AM4接口,所以现有主板从物理接口上是兼容的,而且实际上AMD 500系列主板早就做好了对Ryzen 5000系列处理器的支持。
此前500系列主板的AGESA 1.0.8.0版本BIOS就能点亮Ryzen 5000系列处理器,但要完全发挥性能要更新最新的AGESA 1.1.0.0版本BIOS,这个版本的BIOS能提供最佳的体验,估计是让主板更好的适配新处理器更高的加速频率。
对于还在使用AMD 400系列主板的用户,还是会给出支持新处理器的BIOS的,但不会像500系列主板那样在第一时间得到支持,新BIOS目前AMD还在和主板厂商合作开发中,大概在2021年1月会陆续推出测试版本。
至于AMD 300系列主板,这次是彻底没提到了,估计AMD官方是不会给出支持的了,能不能上Zen 3就完全看板厂心情了。
AMD这次首发的4颗处理器当中只有锐龙5 5600X是带原装散热器的,而且配的是较薄的幽灵Spire,我们手头上两颗锐龙9处理器虽然是不带散热器的,但它内部的空间其实刚好能放进幽灵Spire散热器,估计AMD这次是打算统一所有包装盒的尺寸。
这次要测试的包括16核的锐龙9 5950X与12核的锐龙9 5900X,对比的对象是AMD Zen 2架构同样核心数量的锐龙9 3950X和锐龙9 3900XT,以及Intel的酷睿i9-10900K。AMD平台使用技嘉 X570 AORUS PRO WIFI主板,而Intel平台则使用华硕 ROG MAXIMUS XII EXTREME主板,均使用360一体式水冷散热器,XPG 龙耀D50 DDR4-3600 8GB*2套装,显卡使用NVIDIA GeForce RTX 3090 Founder Edition,SSD是三星 980 PRO 1TB。

需要注意的是我们目前手头上并没有锐龙9 3950X,下面列出的数据是以前测试的记录下来的,所以部分测试会没有锐龙9 3950X的数据,游戏测试也没有锐龙9 3950X,不过游戏这部分,采用改良工艺的锐龙9 3900XT其实要比锐龙9 3950X更强一些。

测试使用的技嘉X570 AORUS PRO WIFI主板
由于缓存的改动,Zen 3的内存延迟明显低于Zen 2,同样搭配DDR4-3600内存时延迟从69ns下降到61ns,依然和对手的酷睿处理器有一定差距,但已经改善了不少。L1与L2缓存的带宽有所提升,延迟也降低了一些,但从幅度来看L1更像是CPU频率提升带来的影响 ,L2缓存的速度确实更快了,L3缓存与Zen 2相比带宽减半了,主要是因为L3缓存从原来的16MB*2变成了现在的32MB*2,区块少了一半,但实际上每个CCX对应的L3带宽是没变化的,利用率其实还更高。
这次我们使用了Sandra的处理器多内核效率来测试CPU的内核延迟,测试时关闭了CPU的SMT和超线程,可以看到锐龙9 3900XT在CCX内部通信时延迟其实是很低的,在26到30ns之间,不过一旦跨CCX的话通信延迟就大幅上升,达到了59到73ns,而且同CCD和跨CCD之间是没有区别的,因为跨CCX之间的通信都要经过IOD,所以延迟非常高。
到了锐龙9 5900X和锐龙9 5950X,由于CCX的改动,同CCD里面的核心间通信延迟基本都一样低,跨CCD通信的话延迟和上一代是差不多的,而8核心以下的锐龙5000处理器根本不存在跨CCD通信这一问题,CCX的改动受益最大可能是它们。
我们也测试了酷睿i9-10900K的内核延迟,由于不是MCM设计,所以10个内核之间的通信延迟是几乎一样的,在39到45ns之间,延迟大于AMD的CCX内部通信延迟,但小于跨CCD的通信延迟。
此前AMD两代锐龙处理器在PCMark 10的测试中和Intel的产品是有较明显差距的,到了Zen 2架构差距已经大幅缩小,而现在的Zen 3则是 反超了对手,毕竟Zen 3的单线程性能比Zen 2确实有很明显的提升,而且新的PCI-E 4.0 SSD出现了,存储性能差距比对手只能用PCI-E 3.0的拉得大了。
PCI-E 4.0的最大受益者并不是显卡,因为对显卡来说它根本用不着那么高的带宽,最大的受益者是SSD,现在许多高性能M.2 SSD都已经触碰到了PCI-E 3.0 x4的极限,升级带宽刻不容缓,把通道数升到x8不太现实,M.2接口的规格放在那里,要上x8的只能用AIC,所以最好的方法就是从PCI-E 3.0升到4.0,这样M.2接口的带宽就能从4GB/s翻倍到8GB/s了。
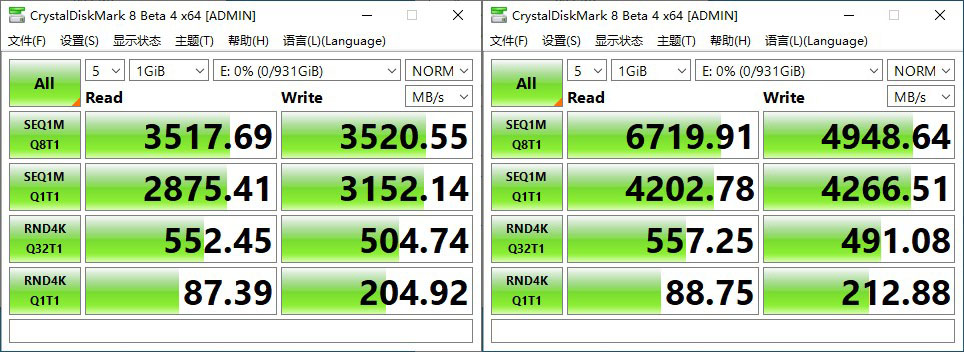
我们用三星980 Pro 1TB测试了它在PCI-E 3.0和PCI-E 4.0时的性能,我们在BIOS里面可以设置PCI-E是Gen几,可见在PCI-E 3.0的时候速度只能去到3500MB/s,这也是现在大多数M.2 SSD的极限速度,不过如果使用PCI-E 4.0的话读取速度能到达6700MB/s,写入速度也能到4900MB/s,限制解除之后连续读写速度明显快了不少,然而随机性能并没有太大变化。现在只有AMD平台能够提供PCI-E 4.0,这也是目前AM4平台的一大优势。
Sandra 2020的处理器计算测试可以测试出处理器的运算能力,一般来说核心数量和线程数量多会更占优势,当然实际结果也得看处理器的频率, 可以看得出的是,Zen 3处理器的浮点运算性能比起Zen 2确实有了很大幅度的提升,整数性能也有一定提升,但幅度没有浮点那么大 ,至于那个酷睿i9,只有10个核,在这种纯算力的测试里面被16核与12核吊打太正常了。
SuperPi是一个完全比拼CPU频率的测试,是单线程的测试,这项测试里酷睿i9-10900K虽然还是第一,但差不多被锐龙9 5950X追上了,但锐龙9 5900X和锐龙9 5950X之间差距有点大,估计是BIOS的原因。
wPrime的算法和SuperPi不一样,所以出来的结果完全不一样,单线程测出来的结果5个处理器几乎一模一样,多线程测试里面Zen 2架构的甚至比Zen 3的跑得更快,比较神奇的一个结果,当然与10核的酷睿i9-10900K比起来肯定是全胜的。
国际象棋测试由于最多只能测试16个线程,所以这里只用来测试处理器的单线程性能,两个Zen 2架构的单线程性能都比酷睿i9-10900K更低,但两颗Zen 3的就反超了差不多10%的性能。
7-zip使用内置的Benchmark测试,Zen 3架构的两颗锐龙5000处理器表现都非常出色 ,压缩测试是无法使用CPU的全部线程的,所以12核与16核的差距不大,两颗Zen 3的领先Zen 2大概10%的性能,解压缩就可完全使用CPU的所有线程,锐龙9 5900X甚至比锐龙9 3950X还要强一点,可见Zen 3的IPC真的提升非常大,锐龙9 5950X的解压缩能力甚至是酷睿i9-10900K的一倍。
3DMark的物理测试,除了不能使用CPU全部线程的TimeSpy基本测试外其他两个测试都是AMD的锐龙处理器完胜,FireStrike测试中锐龙9 5900X的测试结果甚至高于锐龙9 3950X,但在压力更大的TimeSpy Extreme测试中就比不过16核了,但依然可以看出它比锐龙9 3900XT有非常大的性能提升。
x264以及x265是两个老牌开源编码器,应用相当广泛,这次我们使用了新版本的Benchmark,它能更好的支持AVX 2指令集。 在这项测试中即使是12核的锐龙9 5900X也可以胜过上代旗舰16核的锐龙9 3950X,这应该就是浮点算力增加带来的结果。
Corona Renderers是一款全新的高性能照片级高真实感渲染器,可以用于3DS Max以及Maxon Cinema 4D等软件中使用,有很高的代表性,这里使用的是它的独立Benchmark, 同样的在这项测试里面锐龙9 5900X性能也是要高于锐龙9 3950X的,看来浮点算力的提升对渲染软件提升非常大,在看核心数量的渲染软件中,AMD锐龙处理器基本是完胜对手。
POV-Ray是由Persistence OF Vision Development开发小组编写的一款使用光线跟踪绘制三维图像的渲染软件,其主要作用是利用处理器生成含有光线追踪效果的图像帧,软件内置了Benchmark程序。 单线程测试里面两颗Zen 3处理器完全超过了对手的酷睿i9-10900K,多线程测试的话,肯定是核心数量更多的锐龙处理器的天下,可以看得出Zen 3处理器基本上比Zen 2的提升了10%甚至更高。
Blender是一个开源的多平台轻量级全能三维动画制作软件,提供从建模,雕刻,绑定,粒子,动力学,动画,交互,材质,渲染,音频处理,视频剪辑以及运动跟踪,后期合成等等的一系列动画短片制作解决方案,我们使用的是最新的2.90版本,现在只用测试工程来测试CPU的单线程性能,多线程测试使用官方的Benchmark工具。 单线程测试,虽然说还是酷睿i9-10900K排第一,但两颗锐龙5000系列处理器已经和它差不多了,性能比上代的锐龙3000有了非常明显的提升。
多线程测试只测试了Benchmark里面的bmw27与classroom两个项目,上表是两个项目的总耗时,锐龙9 5900X的用时比锐龙9 3900XT缩短了10%以上,可见Zen 2到Zen 3之间的提升是非常大的,核心数量多的优势也很明显,酷睿i9-10900K被远远抛下。
CINEBench使用MAXON公司针对电影电视行业开发的Cinema 4D特效软件的引擎,该软件被全球工作室和制作公司广泛用于3D内容创作,而CINEBench经常被用来测试对象在进行三维设计时的性能,这项测试是AMD的强项,锐龙9 5950X的单线程直接跑到了640分,多线程更是直接突破10000分,锐龙9 5900X的单线程也有634分,比自己的上一代以及对手竞品都高得多。
游戏测试全部都是在1080p分辨率下进行的,除了《地铁:离去》这款游戏之外其他都是开启预设最高档的画质设置,而《地铁:离去》用则是Ultra这档设置。 《CS:GO》测试使用了官方的Benchmark地图,并且解锁了最高帧数。
说真的,AMD这一代锐龙5000的游戏性能真的非常强劲,锐龙9 5900X与锐龙9 3900XT相比,平均这么多款游戏下来提升了19%,与酷睿i9-10900K相比的话,11款游戏里面只有4款输了,有一款打平,其他6款全都高于对手,在《英雄联盟》里面甚至要高出对手23%,《CS:GO》里提升幅度也高达14%,可以说Zen 3架构可以彻底颠覆那些还在认为AMD处理器打游戏不行这个顽固的概念。
采用Zen 3架构的锐龙5000系列处理器温度明显更低了,而且待机电压控制明显要低于Zen 2,温度也更低,用AIDA64 FPU来烤机的时候,锐龙9 5900X的频率到了4.25GHz,电压比跑3.95GHz的锐龙9 3900XT低不少,温度也只有70℃,低了8℃,至于那个锐龙9 5950X,它只能跑到3.8GHz,温度60℃,其实上代的锐龙9 3950X也有这个现象,就是烤机的时候温度功耗比锐龙9 3900X还要低。
在功耗测试方面,我们使用专用的设备直接测量主板上CPU供电接口的供电功率, 目前绝大部分主板都只通过CPU供电接口为CPU进行供电,因此CPU供电输入的功率变化基本上就是CPU功耗变化所引起的,监测该接口的功率就可以直接反应CPU功耗的高低。AIDA64的CPU Package功耗以及平台功耗则是进一步的参考数据,用来体现整台平台的功耗组成。
此外必须说明的是,目前我们测量的是主板上CPU供电接口的输入功率,并非直接的CPU供电功率,因此从该理论上来说应该是略高于CPU的实际供电功率,而且会更因为主板的不同而产生变化,但是这个测试数据仍然有很高的参考价值,因为电源实际上是对主板进行供电而非直接对CPU进行供电,因此对于电源的选择来说,直接测试CPU供电接口的供电功率更有实际意义。
待机的功耗优于AMD锐龙处理器是MCM封装,而且锐龙9处理器里面都有三个芯片,所以待机功耗确实没对手那么好,不过和自己的Zen 2处理器相比,Zen 3的待机功耗确实降低了。
而16核的锐龙9 5950X的满载功耗要比12核的锐龙9 5900X更低,平均功耗低了9W,峰值功耗低了12W,比较它负载时的频率与电压要低得多,而锐龙9 5900X的功耗则要比锐龙9 3900XT低3W,虽然说负载频率要高不少,但电压更低,至于对手的酷睿i9-10900K,完全没眼看。
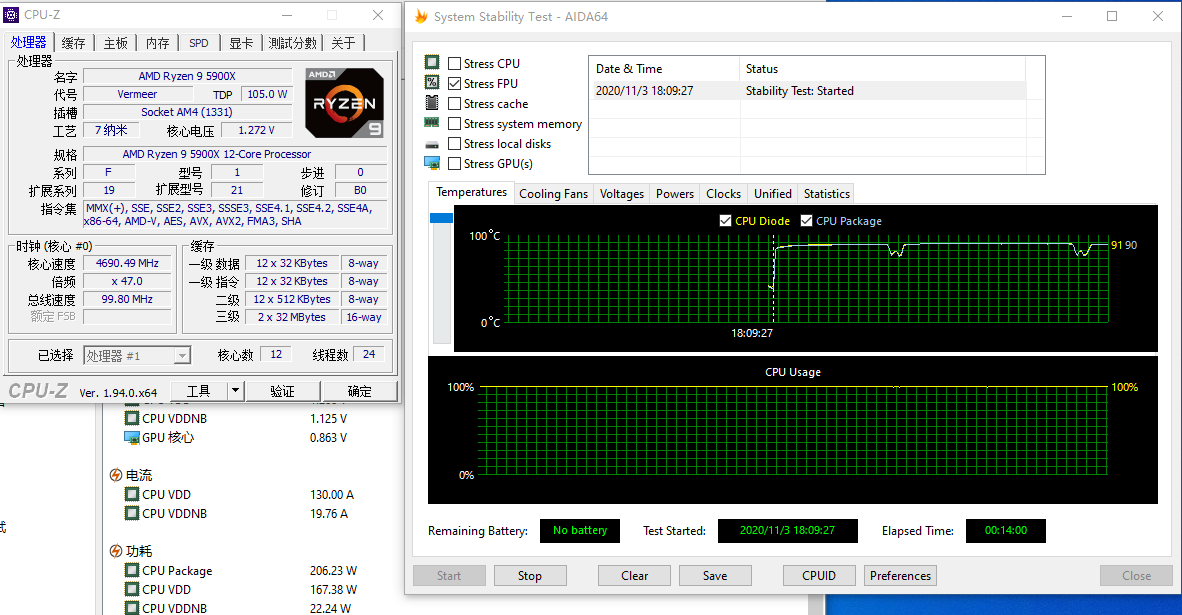
超频我们只跑了锐龙9 5900X,用的新版RyzenMaster软件,Zen 3的超频能力又上了一个台阶,我们手头上这颗锐龙9 5900X能超到4.7GHz,电压加到1.272V,能稳定通过AIDA64 FPU烤机测试,不过这时温度已经有点压不住的迹象了,CPU Package功耗206W,4.8GHz能开机,但跑不了重载测试,而上一代的基本上4.4GHz就到顶了。
上一代Zen 2处理器AMD进行了大刀阔斧的改革,大胆采用MCM封装,把I/O模块独立出来强化了CPU的核心拓扑能力,让最大核心数量从8核翻倍到16核,内核也进行了各种优化也让IPC提升了15%,而到了Zen 3,IOD部分没改,对CCD内的CCX进行了大幅改动,把CCD内的两个4核CCX融合成一个8核CCX,L3缓存也整合成一整块,这有效降低了CPU核心之间的通信延迟,L3缓存的利用也变得更为高效,核心内部也进行了各种改动,我们测出来单线程性能比Zen 2提升了12%之多,而且功耗方面也有所下降,能用更低的功耗达到更高的频率,能耗比有不少提升。
CCX的改动带来的收益很明显,就是降低了各种各样的延迟,这让锐龙5000系列处理器的游戏性能大幅度提升,锐龙9 5900X游戏性能比锐龙9 3900XT整体提升了19%,和对手的酷睿i9-10900K相比也高了3.6%,以往Zen 2处理器即使多线程性能还有拓扑能力如何比对手酷睿处理器强也有人拿游戏性能来挖苦它,但现在游戏性能不再是AMD的短板,最强游戏处理器不再是酷睿i9-10900K了。
至于多线程性能,12核与16核的锐龙9处理器打对手的10核酷睿i9是怎么打怎么赢的,我觉得就不用再多说些什么了。
锐龙5000处理器的价格比锐龙3000的上市价是略微有所上升,但性能提升了这么多,加一点价也是正常,不过上代人气较高的锐龙7 3700X和锐龙5 3600的继任者没有出现在首发名单上,不知道AMD什么时候才会把剩下的锐龙5000系列处理器推向市场。
目前来说,Zen 3的这几款处理器面对对手的Comet Lake是毫无悬念轻松取胜,但真正的强敌是Intel明年第一季度推出的Rocket Lake,由于换了架构估计游戏性能也会提升不少,到时游戏性能谁胜谁负不好说,但多核性能AMD几乎是赢定了,毕竟Rocket Lake最多只有8核,16核打8核应该是没什么悬念。当然了这都是明年第一季度之后的事情了,还有好几个月呢,现在高喊那六个字母就行了。

我匿名了 2020-11-09 10:55
138#
超能网友一代宗师 2020-11-06 18:05 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(21) | 反对(1) | 举报 | 回复
90#
超能网友教授 2020-11-06 10:16 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(84) | 反对(0) | 举报 | 回复
73#
超能网友教授 2020-11-06 08:37 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(94) | 反对(0) | 举报 | 回复
63#
超能网友一代宗师 2020-11-06 00:25 | 加入黑名单
52#
超能网友研究生 2020-11-29 23:22 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有3次举报支持(1) | 反对(13) | 举报 | 回复
157#
超能网友终极杀人王 2020-11-11 23:38 | 加入黑名单
156#
超能网友终极杀人王 2020-11-11 23:27 | 加入黑名单
155#
超能网友终极杀人王 2020-11-11 22:37 | 加入黑名单
154#
游客 2020-11-11 21:24
支持(4) | 反对(0) | 举报 | 回复
153#
超能网友研究生 2020-11-11 21:17 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(3) | 反对(0) | 举报 | 回复
152#
超能网友终极杀人王 2020-11-11 20:15 | 加入黑名单
151#
游客 2020-11-11 15:20
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(7) | 反对(0) | 举报 | 回复
150#
游客 2020-11-11 01:37
已有1次举报支持(4) | 反对(1) | 举报 | 回复
149#
我匿名了 2020-11-10 21:13
支持(11) | 反对(0) | 举报 | 回复
148#
超能网友终极杀人王 2020-11-10 20:02 | 加入黑名单
147#
超能网友终极杀人王 2020-11-10 19:59 | 加入黑名单
146#
游客 2020-11-09 22:05
已有1次举报支持(9) | 反对(0) | 举报 | 回复
145#
超能网友一代宗师 2020-11-09 22:04 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(3) | 反对(0) | 举报 | 回复
144#
游客 2020-11-09 22:00
支持(3) | 反对(0) | 举报 | 回复
143#
我匿名了 2020-11-09 21:55
支持(6) | 反对(0) | 举报 | 回复
142#
游客 2020-11-09 20:22
已有1次举报支持(4) | 反对(0) | 举报 | 回复
141#
超能网友研究生 2020-11-09 20:19 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(4) | 反对(0) | 举报 | 回复
140#
超能网友终极杀人王 2020-11-09 19:49 | 加入黑名单
139#
游客 2020-11-09 09:21
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(7) | 反对(0) | 举报 | 回复
137#
游客 2020-11-08 22:56
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(10) | 反对(0) | 举报 | 回复
136#
超能网友终极杀人王 2020-11-08 19:27 | 加入黑名单
135#
我匿名了 2020-11-08 19:26
支持(15) | 反对(0) | 举报 | 回复
134#
超能网友终极杀人王 2020-11-08 19:24 | 加入黑名单
133#
我匿名了 2020-11-08 17:44
支持(6) | 反对(1) | 举报 | 回复
132#
提示:本页有 11 个评论因未通过审核而被隐藏
加载更多评论