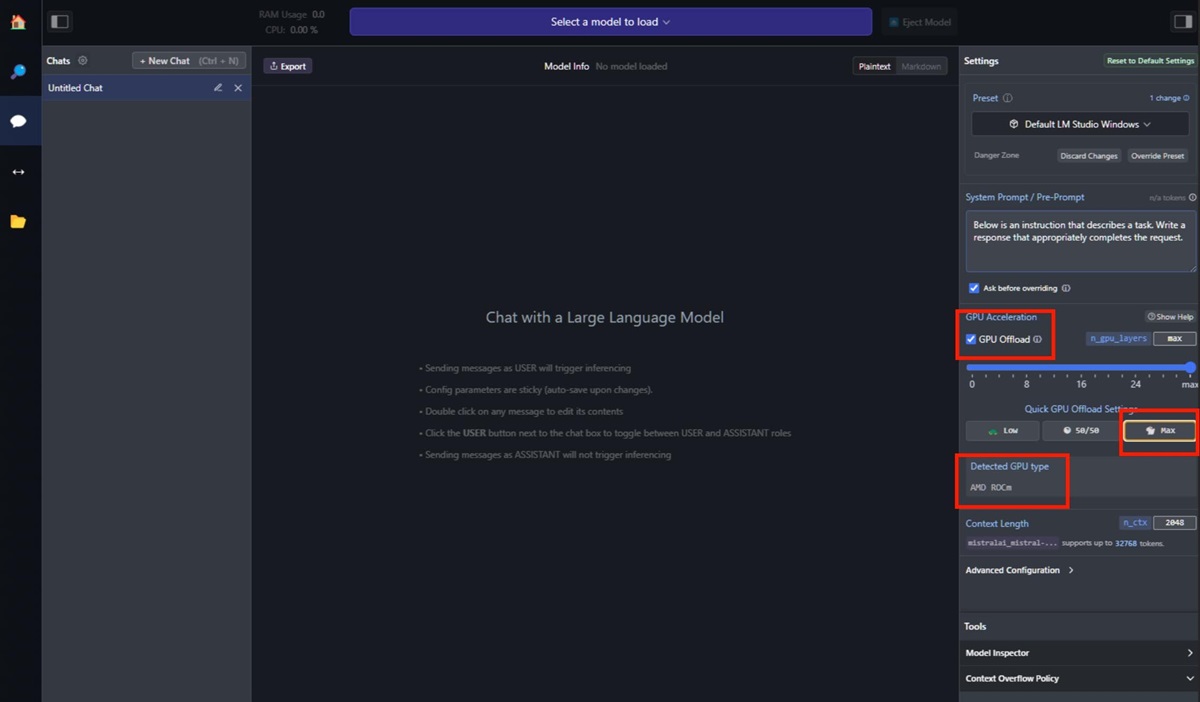
继英伟达发布Chat with RTX以后,AMD现在也为用户带来了可以本地化运行基于GPT的大语言模型(LLM),用户可以此构建专属的AI聊天机器人,可以在具有XDNA NPU的Ryzen 7000/8000系列及内置AI加速核心的Radeon RX 7000系列GPU设备上运行,需要下载对应版本的LM Studio。

AMD表示,人工智能助手正迅速成为帮助提高生产力、效率甚至集思广益的重要来源。在用户自己设备的本地AI聊天机器人不仅不需要互联网连接,而且对话可以保留在本地系统上。
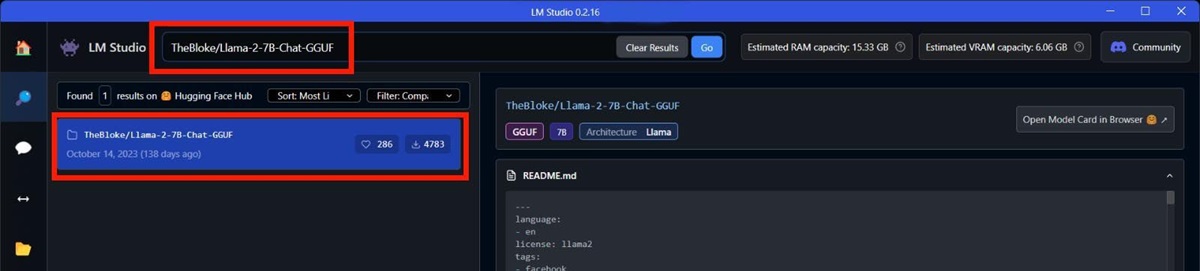
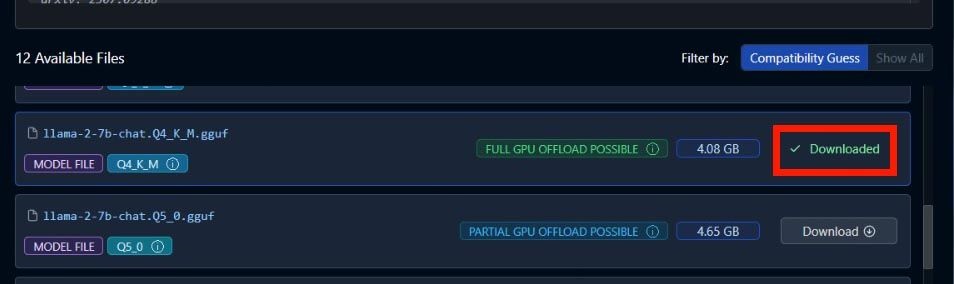
AMD在博客文章中提供了完整的运行步骤,并有具体的用例说明:如果想运行Mistral 7b,搜索“TheBloke/OpenHermes-2.5-Mistral-7B-GGUF”,例子中使用的是Mistral;如果想运行LLAMA v2 7b,搜索“TheBloke/Llama-2-7B-Chat-GGUF”,并从左侧结果中选择,通常是第一个结果。

感兴趣的AMD用户,如果有使用相应的CPU或GPU,可以参照原文进一步了解,按照相应的说明进行操作。
竞争对手英伟达是在上个月发布了Chat with RTX,作为一个技术演示应用,可以让用户以自己的内容定制一个聊天机器人,结合了检索增强生成、TensorRT-LLM和NVIDIA RTX加速技术。用户可以把PC上的本地文件作为数据集连接到开源的LLM,比如Mistral或Llama 2上,支持.txt,.pdf,.doc/docx,.xml等多种文件类型,只需要给出文件夹路径,AI就会在数秒内把它们加载到库中。

红色的龙博士 03-08 11:09 | 加入黑名单
早说了,7000系的卡的AI加速器肯定是有用的,先是ZLUDA,然后是FSR,现在聊天也可以用上这个硬件了
已有1次举报支持(1) | 反对(0) | 举报 | 回复
2#
我匿名了 03-08 09:03
我有理由懷疑不用多久,所有賣到中國的CPU裡邊都只能是去除NPU的純淨版,或者是生產時就已經硬件閹割的特供版GPU。
已有4次举报支持(5) | 反对(4) | 举报 | 回复
1#
提示:本页有 2 个评论因未通过审核而被隐藏