昨晚AMD果然举行了Next Horizon”大会,主题当然就是7nm产品,除了7nm Zen 2内核处理器外,少不了7 nm显卡,首发产品却是面向计算领域的Radeon Instinct计算卡——Radeon Instinct MI 60、Radeon Instinct MI 50。

Radeon Instinct MI 60/50依旧是基于Vega架构演进而来,7nm工艺加持下,晶体管密度增加一倍,在331mm2的核心面积中集成了132亿晶体管,作为参考14nm Vega核心核心面积484mm2晶体管数量却为125亿,进步相当明显。
QYD.png)
新工艺还带了额外的“红利”,在相同功耗情况下,性能提升25%;同样频率下,功耗下降50%,7nm工艺真的足够诱惑,毕竟解决了很多AMD显卡以往积累下来的问题。
AMD还很喜欢讲Vega是一个高度灵活的高性能架构,不过这一次7nm Vega核心架构似乎更加偏向于专业方面,拥有目前世界上最快的FP64/FP32 浮点性能、HBM 2显存、显存ECC纠错功能、唯一的硬件虚拟化,适用于机器学习训练。

这一次AMD给Radeon Instinct计算卡配备了32GB HBM2显存,使得显存带宽突破了1TB/s大关,并支持ECC纠错技术,这些都意味着专门应用于计算领域,游戏领域可用不上这么夸张的显存容量、带宽。

我们目前显卡均采用PCI-E 3.0接口,而7nm Vega架构率先完成了对PCI-E 4.0的适配支持,配合AMD专有的Infinity Fabric总线,支持四张Radeon Instinct计算卡同时并行运算,具备极佳的扩展性,而且这种架构下,显卡性能得到最大提升,双卡几乎是100%提升。

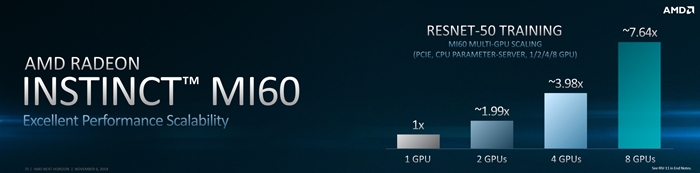
目前Radeon Instinct MI 60、Radeon Instinct MI 50的具体规格依然是保密的,不过AMD也提供了一些性能参考数据,Radeon Instinct MI 60双精度性能为7.4 TFLOPS,单精度翻倍至14.7 TFLOPS,整数性能118 TLOPS。这个数值与NVIDIA的Tesla V100显卡单精度浮点15 TFLOPS,双精度浮点7.5 TFLOPS相近。

Radeon Instinct MI 50具体规格、性能将会稍后公布,两张7nm Radeon Instinct显卡均会在今年出货,而7nm游戏显卡将会在明年与大家见面,至于是Vega架构还是Navi架构,大家猜一猜?



超能网友博士 2018-11-10 01:14 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
19#
超能网友博士 2018-11-08 19:18 | 加入黑名单
支持(2) | 反对(0) | 举报 | 回复
18#
超能网友一代宗师 2018-11-08 19:02 | 加入黑名单
已有7次举报支持(0) | 反对(7) | 举报 | 回复
17#
超能网友博士 2018-11-08 18:50 | 加入黑名单
支持(4) | 反对(1) | 举报 | 回复
16#
超能网友一代宗师 2018-11-08 18:45 | 加入黑名单
已有7次举报支持(0) | 反对(7) | 举报 | 回复
15#
超能网友博士 2018-11-08 18:32 | 加入黑名单
支持(3) | 反对(0) | 举报 | 回复
14#
超能网友一代宗师 2018-11-08 18:23 | 加入黑名单
已有6次举报支持(0) | 反对(6) | 举报 | 回复
13#
超能网友博士 2018-11-08 00:45 | 加入黑名单
支持(0) | 反对(1) | 举报 | 回复
12#
超能网友终极杀人王 2018-11-07 23:21 | 加入黑名单
已有4次举报支持(0) | 反对(4) | 举报 | 回复
11#
超能网友博士 2018-11-07 22:07 | 加入黑名单
支持(5) | 反对(0) | 举报 | 回复
10#
超能网友一代宗师 2018-11-07 21:24 | 加入黑名单
已有11次举报支持(1) | 反对(12) | 举报 | 回复
9#
游客 2018-11-07 17:39
该评论年代久远,荒废失修,暂不可见。
支持(1) | 反对(2) | 举报 | 回复
8#
游客 2018-11-07 15:53
该评论年代久远,荒废失修,暂不可见。
支持(0) | 反对(0) | 举报 | 回复
7#
超能网友博士 2018-11-07 13:35 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
支持(2) | 反对(0) | 举报 | 回复
6#
游客 2018-11-07 13:24
该评论年代久远,荒废失修,暂不可见。
支持(1) | 反对(1) | 举报 | 回复
5#
超能网友博士 2018-11-07 13:14 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有4次举报支持(12) | 反对(4) | 举报 | 回复
4#
游客 2018-11-07 12:57
该评论年代久远,荒废失修,暂不可见。
已有7次举报支持(4) | 反对(7) | 举报 | 回复
3#
超能网友博士 2018-11-07 12:14 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有6次举报支持(2) | 反对(7) | 举报 | 回复
2#
游客 2018-11-07 12:10
该评论年代久远,荒废失修,暂不可见。
支持(3) | 反对(1) | 举报 | 回复
1#