之前的课堂文章中我们介绍了NVIDIA显卡从Kepler架构到Turing架构的演变史,今天这个就是姊妹篇AMD显卡架构演变史了,更准确地说是GCN架构这七年来的变动,因为从2012年推出GCN架构之后AMD就在打磨GCN上停不下来了。

在GCN架构之前,AMD在GPU架构上也探索过了很多方案,这时候AMD已经接管了ATI的GPU研发,2006年收购ATI时AMD有个很重要的梦想就是用GPU弥补CPU计算的不足,有些玩家可能还记得AMD当年大力宣传的异构计算吧,还拉拢了ARM、三星等公司组成了HSA异构运算基金会推CPU+GPU运算。


AMD将2002之前、2002到2006、2007年到2012的GPU发展分为三个阶段,第一阶段是固定单元,专注游戏性能,第二阶段是简单渲染,第三阶段则是并行GPU运算,AMD接受ATI后已经是第三个阶段了。

ATI的绝唱是XT1900系列,HD 2000及之后就是AMD主导了,这个时代直到HD 6000系列,由TeraScale架构主导,其中比较重要的节点有HD 4800系列、HD 5800及HD 6900系列,代号Cypress的HD 5800时代开始上DX11了,代号Barts的HD 6800系列在HD 5800基础上修改,提高能效,而代号Cayman的HD 6950则将TrgeaScale发展到巅峰,核心架构也从之前的VLIW5升级到了VLIW4。

对于这个架构的变化,多年前超能网的评测中也做过详细解释了:
在Cayman核心中,VLIW处理器中的ALU数量被精简到了4个,抛弃了VLIW5处理器中的ALU.trans,我们称Cayman的这种VLIW为VLIW4处理器。应该说Cayman核心是自R600以来,在硬件架构上变动最大的一个。VLIW4回归到了传统ALU的4D模式,只是变成了更灵活的4个1D。对于一个部门来说,显然管理4个人比管理5个人更简单高效,或许AMD也是这么想的。
和VLIW5不同的是,VLIW4中的四个ALU功能都是对等的,可以实现4-way Co-issue操作,原来由ALU.trans完成的特殊函数操作现在也可以交给这四个ALU来完成了,不过一个特殊函数操作需要占据四个指令发射中的3个。
AMD声称,VLIW处理器结构的改变(VLIW5->VLIW4),同样核心面积的条件下能带来10%的性能提升,简化了指令调度和寄存器管理,提升逻辑电路利用率。不过从VLIW5改变到VLIW4,随之而来的是晶体管和功耗的大幅增加,这是不得不付出的代价。

在整个TeraScale时代,可以看出来AMD一直在改进VLIW架构的效率,AMD此前表态VLIW架构非常适合图形运算,但GPU计算不太好,这个判断也会影响后来的架构设计,因为AMD念念不忘的就是GPU计算。

另外,在HD 4800到HD 6900的时候,个人都很喜欢公版AMD显卡的外观设计,那时候AMD显卡的PCB设计及用料也很扎实,虽然涡轮单风扇噪音问题一直有点无解,但总体来看颜值还是很高的。
在VLIW架构下折腾了多年,AMD终于在2012年初(2011年底就发布了)推出了HD 7970显卡,核心代号Tahiti塔西提,架构则是Graphic Core Next,GCN架构闪亮登场,距离现在已经7年了,但GCN架构依然是AMD显卡的基础,堪称史上最长寿的GPU架构。
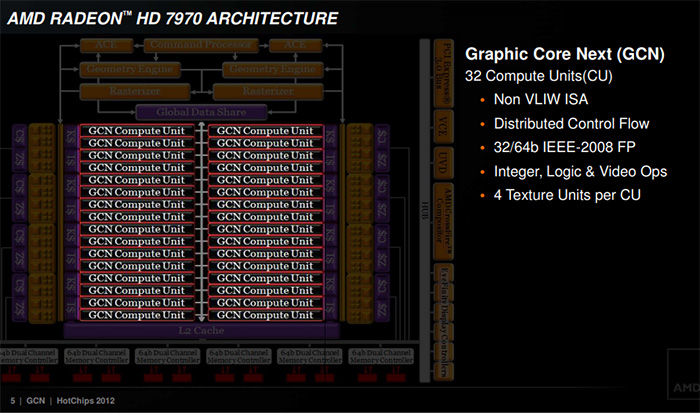
当年HD 7970的首发评测中,我们称其为图形、显卡双冠王,这个标题就是AMD要在GCN架构上实现的目标——不仅要游戏性能强大,还要灵活应对GPU计算时代,要提高GPU的多线程处理能力,优化高性能计算,提高扩展能力和弹性,所以GCN架构的计算性能提升是最明显的,我们当年的首发评测也证实了这方面的进步。
GCN架构中基本的组成单元为“Compute Unit”(简称CU),完整的GCN核心有32个CU单元,每个CU单元又下辖64个ALU单元和4个TF纹理单元,总计有2048个ALU计算单元,128个纹理单元,相比之下HD 6970的流处理器单元只有1536个,纹理单元也只有96个。
前端部分延续了HD 6970显卡所用的“Dual Graphic Engines”双图形引擎结构,有两个ACE(Asynchronous Compute Engines异步计算引擎)和两个Geometry Engines(几何引擎,第9代曲面细分单元)引擎。
HD 7970还有8个后端渲染单元,每周期可以实现32个ROP光栅渲染和128个Z/stencil渲染,这一点与HD 6970倒是没有分别,不过显存位宽加大了,后端处理性能还是有提升的。
32个CU单元之外是6组GDDR5显存控制器,每组64bit,显存位宽为384bit,这也是AMD首次使用384bit显存位宽,再结合1375MHz的高速度,HD 7970的显存带宽达到了264GB/s,显存容量也再上一个台阶,达到了3GB。

与VLIW 4体系的一组SIMD阵列相比,二者的ALU单元总数是相同的,每个CU以及SIMD阵列单元都能执行64个单精度混合乘加运算,好比16*4和4*16都等于64一样,但是区别在于,VLIW 4每次虽然可以执行4个ALU运算,但是每个ALU单元不能独立运算,需要组合成VLIW 4才可以,效率和调度是个问题,而GCN的4 SIMD阵列每周期可以执行1个ALU运算,但是四组SIMD可以互不依赖,只要有进程就一直是100%效率。

内核架构的改进说起来只是GCN架构大变身的一部分,HD 7970显卡身上还有其他闪光点,比如首发支持28nm工艺、PCIe 3.0、改进曲面细分、Eyefinity宽域2.0多屏扩展、HD3D立体显示、UVD视频引擎、ZeroCore功耗管理等等,几乎涉及显卡性能、功耗、发热、显示、视频编码等方方面面,可以说GCN架构加持的HD 7970显卡从内到位都是焕然一新的。

HD 7970显卡一问世就好评不断,不论是对家自家上代旗舰还是NVIDIA当时的旗舰产品都有明显的优势,计算及游戏性能大幅领先,NVIDIA直到3个月后推出GTX 680才算勉强扳平。AMD在第一代GCN架构之后也在不断改进,于2013年10月底的R9 290X显卡上正式推出了新一代GCN架构Hawaii核心。

对于GCN架构的断代,AMD最初的说法是GCN 1.0、GCN 1.1、GCN 1.3等等,这个命名可以看出GCN架构是小幅升级的,但在2016年的Polaris架构中AMD时任GPU老大Raja Koduri大笔一挥,将命名方式改为GCN 1.0、GCN 2.0、GCN 3.0直至Vega的GCN 5.0,这篇文章萨我们就基于最新的官方命名体系,所以原本是GCN 1.1的Hawaii核心就是GCN 2.0架构了。
考虑到HD 7970的GCN 1.0架构打下了足够好的基础,GCN 2.0作为改良版没有大修大建的必要,所以Hawaii核心的官方定性就是GCN架构持续进化,首先是大幅扩增了CU单元数量,从HD 7970的32组CU单元提升到了44组CU单元,它由4组Shader Engine渲染引擎组成,每组渲染引擎又包含11组CU单元,每组CU单元的组成基本不变,这样一来CU单元总数就从原来的32组提高到了44组,流处理器单元数量从2048提高到了2816个,纹理单元则达到了176个。

此外,几何单元和光栅单元也被放到了渲染单元中,Hawaii核心的几何单元数量就从原来的2组变成了4组,而ROP单元从原来的32个暴增到64个。
在Hawaii架构中值得关注的改进还有前端单元,ACE异步计算引擎从之前的2组提高到了8组,而且Hawaii的ACE单元执行能力大幅提升,每周期可管理8个队列,Tahiti核心中的ACE每周期只能管理2个队列,总的管理能力从每周期4队列提升到了每周期64队列。
另一个值得注意的地方是显存位宽,Hawaii核心将成为Radeon HD 2900XT之后另一个采用512bit显存位宽的显卡了,此前包括NVIDIA的GK110和AMD的Tahiti核心在内的一众旗舰显卡都只用了384bit位宽。
AMD设计师解释称他们仔细评估了高频率+低位宽与低频率+高位宽两种显存设计的利弊,认为高位宽+低频率的组合还是要优于前者,通过优化,521bit显存控制器占用的面积反倒比之前384bit位宽更低20%,因此Hawaii选择了512bit位宽,这样一来显存频率不需要太高就能达到极高的带宽。
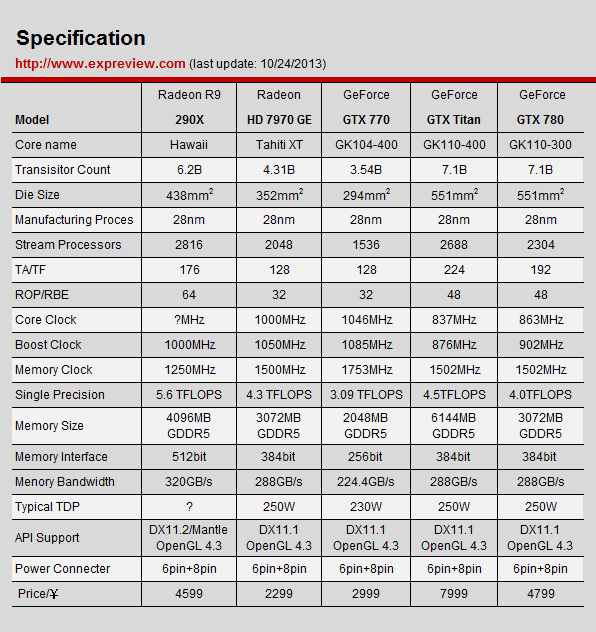
回头看看当时的首发评测,里面提到代一句话——“Hawaii的8个ACE单元设计跟PS4是一样的,管理能力也是一样的,据说这是索尼建议AMD改进的。”在当时认为AMD官方这么说没什么特别的意思,现在结合去年爆出的信息,可以说AMD之前为索尼、微软设计主机处理器对他们设计桌面GPU的影响很大,现在来看AMD的选择就有一种豁然开朗的感觉了,怪不得AMD GPU上会有一些对PC游戏来说看似没什么用或者说不明所以的设计,根子就是在主机处理器上。

在GCN 2.0架构中还有一个新的技术,那就是TrueAudio音频技术,号称世界首款可编程音频渲染技术,在Hawaii核心里还有一部分电路是给TrueAudio准备的,集成了Tensilica公司的多声道HiFi EP音频DSP单元,支持自定义编程。
AMD认为目前只有10%的CPU性能是用来处理音频的,这限制了游戏开发者进一步提高游戏的音效,而且USB音频驱动带来的也只是虚假的3D音效,而在TrueAudio专用的音效单元中,开发者可以借助可编程音频单元实现更好、更逼真的3D音效,提升了玩家的游戏体验,同时专用的电路也可以降低CPU的负担,解释运算资源。
此外,R9 200系列显卡的GCN 2.0架构还有一些技术值得关注,比如名噪一时的Mantle优化,在DX12/Vulkan没来之前,AMD的Mantle优化了底层硬件的效率,虽然最后AMD也不再推Mantle了,但Mantle使命已达,影响了DX12及Vulkan API的发展,功不可没。
还有就是XDMA交火技术,不需要软桥或者硬桥就能连接多卡,这给玩家省了一笔费用,而友商可是把SLI硬桥当作信仰充值的工具的。

尽管GCN 2.0架构的Hawaii核心技术上亮点不少,性能也很强大,但是R9 290X显卡作为旗舰卡却是翻车了,提升性能的同时功耗也大幅增加了,导致R9 290X散热、噪音表现不佳,94°C的温度让不少玩家望而却步,特别是国内玩家对显卡低温很敏感,再加上4599元的价格,这个价格及其表现吓阻了玩家拥有R9 290X显卡的决心。
R9 200系列高端显卡的表现不尽如人意,除了导致AMD损失显卡份额之外,也让AMD没动力大幅升级GCN架构了,因为AMD当时还在搞另一件大事,所以2015年的时候AMD让以往4000+高端市场的R9 290系列显卡玩起了马甲战术,变成了3000出头的中高端显卡,推出了R9 300系列显卡,其中R9 390X虽然名义上市新的Grenada核心,但2816个流处理器单元、512bit位宽等规格与R9 290X的Hawaii核心没变,只是GPU核心频率从1000MHz提升到1050MHz,显存容量翻倍到8GB。
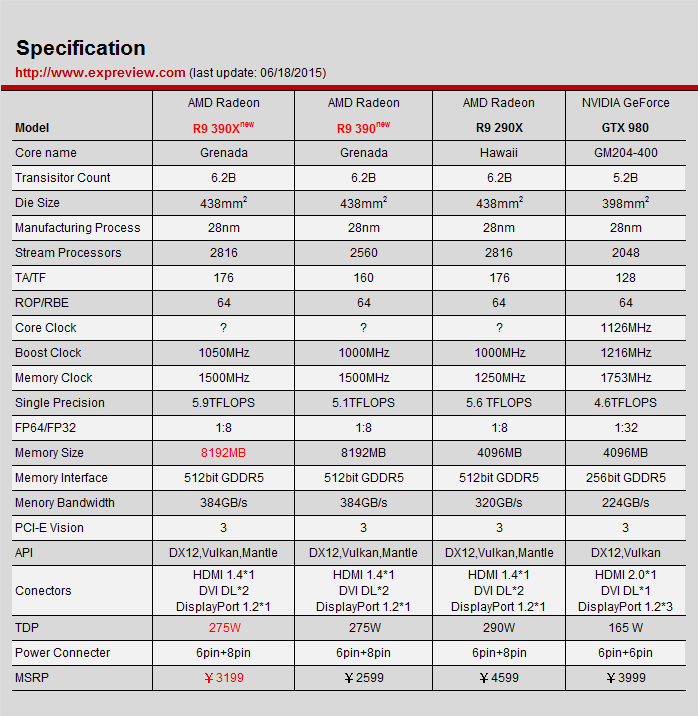
R9 390系列显卡规格
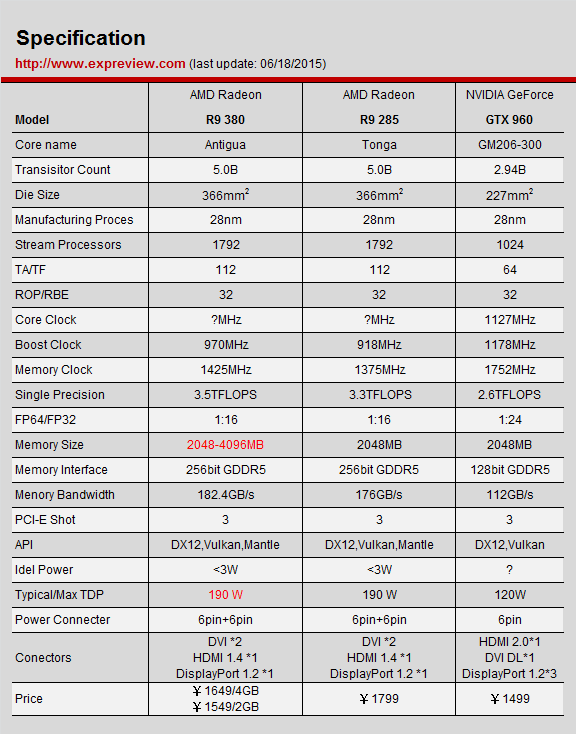
R9 380系列显卡规格
值得一提的是,AMD跟当年的NVIDIA一样,高端显卡的GPU核心不一定有架构升级,但是中端核心可能就会首先尝试新架构,R9 285显卡的Tonga核心就不同于GCN 2.0,在官方认定中它是跟下面的Fiji核心一样是GCN 3.0时代的,只不过不像后者那样用上了HBM显存。
2015年的时候R9 390系列不再是AMD的旗舰卡了,所以它的价格大幅下滑,因为有比它更厉害的显卡问世了,那就是全新的R9 Fury系列,这些显卡使用的是Fiji核心,跟Tonga核心一样都是GCN 3.0架构的,在这一代中AMD再次扩增了GCN架构的CU单元数量,达到了64组,总计4096个流处理器单元,256个纹理单元,64个ROP单元,核心面积达到了596mm2,晶体管数量则达到了89亿个,比NVIDIA的GM200核心的80亿个还要多。

相对于Hawaii/Grenada核心来说,Fiji前端单元没有变化,同样是8组ACE单元,4组几何单元(曲面细分单元),4组渲染引擎(Shader Engine),但CU计算单元数量增加到了64组,每组渲染引擎单元包含了16组CU单元,之前的Hawaii是每组11个CU单元。
另一个值得注意的变化是显存控制器,Hawaii/Grenada是8组64bit GDDR5主控,总计512bit位宽,而Fiji核心增加了HBM显存支持,所以有4组HBM显存控制器。
实际上HBM显存才是Fiji核心及Fury系列显卡的最大亮点,个人认为这也是显卡多年来变化最大的一次,因为HBM不仅仅是性能更高的显存,还从根本上改变了显卡设计。

对于HBM显存,AMD早在2008年就开始布局研发了,携手ASE、Amkor和UMC联合研发了首个可大批量生产的中介层解决方案,也就是HBM显存。这种方案灵活度也挺大的,一方面可以让显存尽可能地接近逻辑核心,以获得极大的总线位宽和效率、简化通信和时脉,还允许集成不同的技术,未来的新显存技术也能集成到中介层上。

当时GDDR5虽然频率普遍已经达到了1750MHz(实际7000MHz以上),每个封装位宽为32-bit,带宽为28GB/s,每瓦带宽实测10.66GB/s。而第一代HBM频率最高只有500MHz(实际工作频率1000MHz),但是每个封装的总线位宽高达1024-bit,带宽超过100GB/s,电压低至1.3V,每瓦带宽超过35GB/s,实测功耗降低50%以上。

再考虑到空间占用问题,1GB GDDR5需要4颗芯片,而HBM只要一颗7mm×5mm的小芯片,单位容量表面积减少94%,而且因为HBM是和逻辑核心集成在同一块基板上,可以节省更多的空间。虽然PPT上说的只是逻辑核心+显存占据的PCB面积,并非整张显卡PCB的面积,不过可以预见最终显卡也可以做得很短。

在当时AMD一共推出了三款Fiji核心的显卡——R9 Fury X、R9 Fury及R9 Nano,其中Fury X一改之前R9 290X的教训,使用了一体式水冷设计,虽然安装过程麻烦点,但是散热效果非常好,即便是Furmark拷机时,最高温度也只有61°C。至于噪音,这点也无需担心,低负载下风扇转速维持在1000RPM内,最高也不过1300RPM多点,全程都非常安静。

Fury X很好很强大,不过要说我个人最喜欢的显卡还是非R9 Nano莫属,HBM显存带来的高性能、小面积优势在这个显卡上完全体现出来了,真正的ITX小钢炮,而且与Fury显卡相比,AMD在R9 Nano显卡上的功耗调校完全不是一个级别的,频率降至1GHz之内GCN架构的能效还是有一定优势的。

在GCN 3.0的Fiji时代,AMD用HBM显存震惊了业界,但是成也萧何败萧何,HBM显存量产在技术上是一次突破,但尝鲜的代价也不低,别说4年多之前了,迄今为止HBM显存都是高价的代名词,产能、成本都是个问题,导致了Fury系列显卡初期供应并不太好,而且价格也降不下来,那时候面对NVIDIA的Maxwell显卡能效上还是没优势的。
Fiji核心是AMD 28nm工艺节点的绝唱,各项规格也达到了AMD当时的顶峰,但是AMD GCN架构的能效问题越来越严重了,特别是后来NVIDIA推出了Maxwell架构,同样是28nm工艺,能效可是大幅进步的,导致AMD亚历山大,也不得不重视能效问题了,所以他们准备的新方案就是GCN 4.0架构的Polaris核心,升级到了14nm工艺。

根据AMD所示,Polaris除了关注性能提升之外,重点就是优化能效,每瓦性能是前代的2.8x了。

对于Polaris核心显卡,AMD的定位也不一样了,它不再是竞争旗舰级市场,命名也变成了Radeon RX 400系列,其中RX 480具备36组CU单元,远不如Fiji的64组甚至不如Hawaii核心的44组CU单元,而且这36组CU单元中还有4组CU单元是给TrueAudio单元预留的,实际用于图形运算的只有32组CU单元,这就回到了初代GCN的水平了。
不过GCN 4.0架构改进了几何单元、提升了渲染器效率、改进了色彩压缩、L2缓存容量翻倍等等,因此与前代R9 290X显卡相比,其CU计算单元性能提升了15%。

除了GCN 4.0核心架构改进之外,Polaris还改进了视频输出,RX 480显卡支持DP 1.3、HDMI 2.0,并预先支持DP 1.4接口。视频解码编码方面,Polaris架构也做了改进,H.264编码支持4K 30Hz编码,HEVC/H.265则可以支持到4K 60Hz编码。

工艺方面,Polaris也是一次重要的变化,此前AMD的GPU都是TSMC代工的,CPU是GF代工的。从14nm工艺开始,AMD的GPU也有GF公司代工了,最初的说法是AMD会同时使用TSMC 16nm及GF 14nm工艺,但实际上他们只使用了GF 14nm工艺,GPU不再由TSMC台积电代工了。
根据官方资料,14nm工艺使得显卡运行电压降低了150mV,功耗降低了30%,所以Polaris架构使用的14nm工艺相比28工艺能提升70%的每瓦性能比,但在AMD优化之后,新显卡的能效比最终达到了前代水平的2.8倍。

综合RX 480显卡的表现来看,在1999元的售价下它的竞争力还是不错,整机功耗比R9 380X还要低,比NVIDIA的GTX 980/970显卡能效还有一定距离,但已经不是代差了,毕竟他们的价格也差了一大截。

2017年AMD又推出了第二款14nm工艺的显卡,也就是RX 500系列,实际上它也就是14nm Polaris显卡的马甲,主要是提升了频率,RX 580由原来RX 480默认频率的1120MHz提升至1257MHz,boost频率上限增至1340MHz。RX 570也相应提升至1120-1266MHz水平,预期性能增幅9-10%。
2017年真正的新品是RX Vega系列,这一次AMD直接用新核心做为显卡命名,并一直沿用到了现在。虽然我们习惯说是GCN 5.0架构,不过这个说法AMD官方没有提,他们用的说法是NCU计算单元,不过这里出于统一的习惯还是称其为GCN 5.0。

AMD当时的RTG部门主管Raja Koduri在PPT中对Vega的重大改进做了详细介绍,看官方资料绝对是各种鸡血,当时也确实这样的,因为前几年AMD在高端显卡市场就已经乏力了,GCN架构不论性能还是能效相对Maxwell、Pascal都没优势了,大家都希望Vega能够重振AMD高端市场雄风。

从官方资料来看,Vega使用的GCN 5.0架构变化还真不少,主要涉及Vega显卡新一代显存架构、Vega显卡新一代几何渲染管线、Vega显卡新一代NCU单元、Vega显卡新一代像素引擎等,而且这一次AMD又把新一代HBM显存技术用于消费级显卡了(NVIDIA在AMD之前率先在Tesla P100上用了HBM2显存了,但消费级没有大规模推)。
Vega核心虽然还是64组CU单元总计4096个流处理器单元,但内部单元做了改进,AMD宣称是优化了IPC性能,并提高了运算单元的灵活性。
在计算性能上,Vega首度引入了紧缩的半精度计算支持,Vega的微架构被称为“NCU(下一代计算单元)”,每个NCU中拥有64个ALU,它可以灵活地执行紧缩数学操作指令,如每个周期可以进行512个8位数学计算,或者256个16位计算,或者128个32位计算。这不仅充分利用了硬件资源,也大幅度提升Vega在深度学习计算的性能。效果也非常显著,在之前公布的Radeon Instinct MI25计算卡就是基于Vega架构的,其FP32单精度浮点性能12.5TFLOPS,而半精度FP16性能直接翻倍到25TFLOPS。

除了 NCU内核的改进,Vega的重点还是围绕HBM2显存来的,但是这一代的HBM2显存为了减少成本,只用了2颗堆栈,等效位宽从上代Fury X的4096bit降至2048bit,通过频率提升到1890MHz实现了484GB/s的带宽,但比Fury X的512GB/s实际上降低了。

不过AMD为了弥补这个问题,开发了HBCC高带宽缓存控制器,除了显存自身之外,可以连接显卡PCB接入的SSD(Radeon Pro SSG那种)、网络存储、系统DRAM等不同形式的片外存储器件,甚至可以将HBM 2显存作为最后一级缓存使用,将片外存储器件的寻址页面保存在显存中,方便GPU调取外部数据时快速寻址,减少延迟。
在《杀出重围:人类分裂》中,启用了HBCC高带宽缓存控制后,GPU的显存寻址效率提升明显,对应所需的显存大小需求更小,从而提升了游戏画面速度。在帧率优化演示中,启用了HBCC后,游戏平均帧数提升了50%,最小帧率提升一倍,游戏画面非常流畅。

Vega显卡的GCN 5.0/NCU架构纸面上很强大,实际性能也不弱,水冷版RX Vega 64能战GTX 1080显卡,不过RX Vega系列三款显卡整体的表现依然不尽如人意,最高性能拼不过NVIDIA的GTX 1080 Ti等显卡,能效依然是个短板,而且HBM2显存依然是产能低、成本高,让AMD再次吃尽了苦头。
所以说从最初的Fury X到RX Vega,AMD在HBM技术上可以说是先锋,但在商业策略上谈不上成功,反而深受其害。
虽然RX Vega在游戏市场失利,但是AMD幸运地遇到了2017-2018年初的数字货币热潮,而RX Vega及RX 480/580等显卡用于挖矿不错,所以AMD当年并不愁卖,由于挖矿商人们的大肆收购,曾经RX 480、RX 580等热门显卡一票难求,而且大幅涨价到3000元以上。
不过2018年下半年开始,矿卡市场又崩了,留给AMD及NVIDIA一堆库存问题,所以2018年AMD实在出不了新架构显卡了,年底的时候才推出了12nm工艺的RX 590显卡,今年1月初还推出了7nm工艺的Radeon VII显卡,不过大家都知道今年的重点是7nm Navi显卡。

对RX 590来说,其核心及架构都没什么变化的,依然是Polaris那一套的,第四代GCN架构,36组CU单元,36×64=2304个SP流处理器,144个纹理单元,32个ROP光栅单元。显存也同样保持一样的规格,位宽256bit,显存频率8GHz,带宽256GB/s,TDP提升到225W。

最明显的提升就是频率上的变化,RX 580已经由RX 480的1120MHz提升至1257MHz,RX 590再次提升至1545MHz。RX 580到RX 590频率提升在15%左右,可见RX 590性能提升也应当在15%上下。

至于Radeon VII显卡,它使用的依然是Vega核心,不过制程工艺升级到了台积电7nm,14nm Vega显卡核心面积为495mm2,7nm Vega核显面积下降到331mm2,面积缩小了33%,同时晶体管数目也略微增长了5.6%。
此外,Radeon VII最高频率达到了1800MHz,都快追上NVIDIA显卡水平,上一代RX Vega 64风冷版也只有可怜的1546MHz,频率提升幅度在16.5%,这部分频率红利会直接反应到性能表现上。
至于核心架构,第二代Vega架构也没有大动作的变动,主要是做了额外的优化,针对计算增加了一些新的指令集,提高深度学习性能,还有就是提高NCU单元的工作频率、减少传输延迟、增加光栅单元的交互带宽,以此换取更好的游戏性能。

在HBM2显存上,Radeon VII也补全了之前的遗憾,不仅容量翻倍到16GB,而且还是全速4096bit位宽,带宽高达1024GB/s,这样的性能已经超出了游戏卡范畴,所以AMD也一直在强调友商11GB显存的显卡不够用了,16GB才能更好地应付游戏、内容创作等需求。
凭借7nm工艺带来的频率红利及16GB HBM2显存的优势,Radeon VII显卡的性能达到了GTX 2080级别,给AMD 7nm GPU家族开了个好头,不过这样做的代价也不小,功耗、能效依然是AMD的痛,7nm Vega并没有质的改变。

大家期待的关键还是7nm Navi了,这个才是针对主流游戏市场的,本月底的台北电脑展我们就能看到它了。
2012年初GCN架问世时可以说光芒万丈,各项技术指标都要领先AMD及NVIDIA当时的旗舰卡,实现了AMD追求的图形、计算双双突破的目标。如今7年过去了,GCN架构依然是AMD GPU的主力架构,尽管官方表示迭代升级了GCN 2.0、GCN 3.0、GCN 4.0、Vgea NCU等等,但AMD显卡这7年来的核心变化并不多,SIMD阵列64个ALU单元的基本组成没变。
在NVIDIA推出Maxwell、Pascal显卡之后,AMD的GCN架构在能效上的劣势愈发明显,以后来者的眼光来看,GCN这几年来遇到的瓶颈有两部分,一个是CU单元规模,目前依然没有超过2015年的Fiji核心的4096个,Vega也是如此,而另一个瓶颈就是频率,AMD是最早突破1GHz GPU频率的,但是NVIDIA在Pascal架构上可以轻松实现2GHz频率了,可AMD GCN显卡在频率超过1.5GHz之后功耗大增,能效更差了,双方因为架构、代工工艺的选择早已经分道扬镳了。
对AMD及AMD粉丝来说,7nm Navi已经成为今年最大的期待及筹码了,在Fiji、14nm Vega、7nm Vega让人失望之后,Navi的售价及性能将成为AMD显卡今年翻身与否的关键了,可以确定的是它还会使用GCN架构,就看AMD如何改进了。


超能网友教授 2019-05-17 13:56 | 加入黑名单
19#
我匿名了 2019-06-04 21:35
支持(0) | 反对(0) | 举报 | 回复
31#
我匿名了 2019-06-04 21:30
该评论年代久远,荒废失修,暂不可见。
支持(4) | 反对(0) | 举报 | 回复
30#
超能网友终极杀人王 2019-05-19 09:40 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有6次举报支持(1) | 反对(4) | 举报 | 回复
29#
我匿名了 2019-05-18 17:45
已有3次举报支持(8) | 反对(0) | 举报 | 回复
28#
超能网友终极杀人王 2019-05-18 16:35 | 加入黑名单
已有4次举报支持(0) | 反对(4) | 举报 | 回复
27#
超能网友终极杀人王 2019-05-18 11:53 | 加入黑名单
已有1次举报支持(1) | 反对(0) | 举报 | 回复
26#
超能网友小黑屋 2019-05-18 09:30 | 加入黑名单
已有1次举报支持(3) | 反对(0) | 举报 | 回复
25#
超能网友终极杀人王 2019-05-17 23:01 | 加入黑名单
已有3次举报支持(1) | 反对(0) | 举报 | 回复
24#
超能网友终极杀人王 2019-05-17 22:52 | 加入黑名单
已有1次举报支持(1) | 反对(0) | 举报 | 回复
23#
超能网友终极杀人王 2019-05-17 21:59 | 加入黑名单
已有3次举报支持(1) | 反对(3) | 举报 | 回复
22#
游客 2019-05-17 14:41
已有1次举报支持(6) | 反对(1) | 举报 | 回复
21#
游客 2019-05-17 14:36
支持(9) | 反对(0) | 举报 | 回复
20#
超能网友小黑屋 2019-05-17 13:42 | 加入黑名单
支持(4) | 反对(0) | 举报 | 回复
18#
超能网友终极杀人王 2019-05-17 13:09 | 加入黑名单
已有3次举报支持(0) | 反对(2) | 举报 | 回复
17#
超能网友小黑屋 2019-05-17 11:49 | 加入黑名单
支持(4) | 反对(1) | 举报 | 回复
16#
超能网友终极杀人王 2019-05-17 11:44 | 加入黑名单
已有1次举报支持(0) | 反对(2) | 举报 | 回复
15#
超能网友终极杀人王 2019-05-17 11:42 | 加入黑名单
已有1次举报支持(3) | 反对(2) | 举报 | 回复
14#
超能网友终极杀人王 2019-05-17 11:34 | 加入黑名单
支持(6) | 反对(2) | 举报 | 回复
13#
超能网友终极杀人王 2019-05-17 11:29 | 加入黑名单
已有5次举报支持(0) | 反对(4) | 举报 | 回复
12#
我匿名了 2019-05-17 11:18
支持(7) | 反对(0) | 举报 | 回复
11#
超能网友终极杀人王 2019-05-17 11:04 | 加入黑名单
10#
我匿名了 2019-05-17 09:03
9#
超能网友终极杀人王 2019-05-16 22:28 | 加入黑名单
支持(8) | 反对(0) | 举报 | 回复
8#
超能网友终极杀人王 2019-05-16 20:59 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有1次举报支持(0) | 反对(4) | 举报 | 回复
7#
我匿名了 2019-05-16 20:28
已有2次举报支持(10) | 反对(8) | 举报 | 回复
6#
超能网友终极杀人王 2019-05-16 20:21 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有16次举报支持(2) | 反对(11) | 举报 | 回复
5#
超能网友终极杀人王 2019-05-16 20:16 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有6次举报支持(1) | 反对(3) | 举报 | 回复
4#
超能网友终极杀人王 2019-05-16 19:57 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有17次举报支持(2) | 反对(13) | 举报 | 回复
3#
超能网友研究生 2019-05-16 19:41 | 加入黑名单
该评论年代久远,荒废失修,暂不可见。
已有5次举报支持(7) | 反对(9) | 举报 | 回复
2#
提示:本页有 3 个评论因未通过审核而被隐藏
加载更多评论